
Towards Data Science
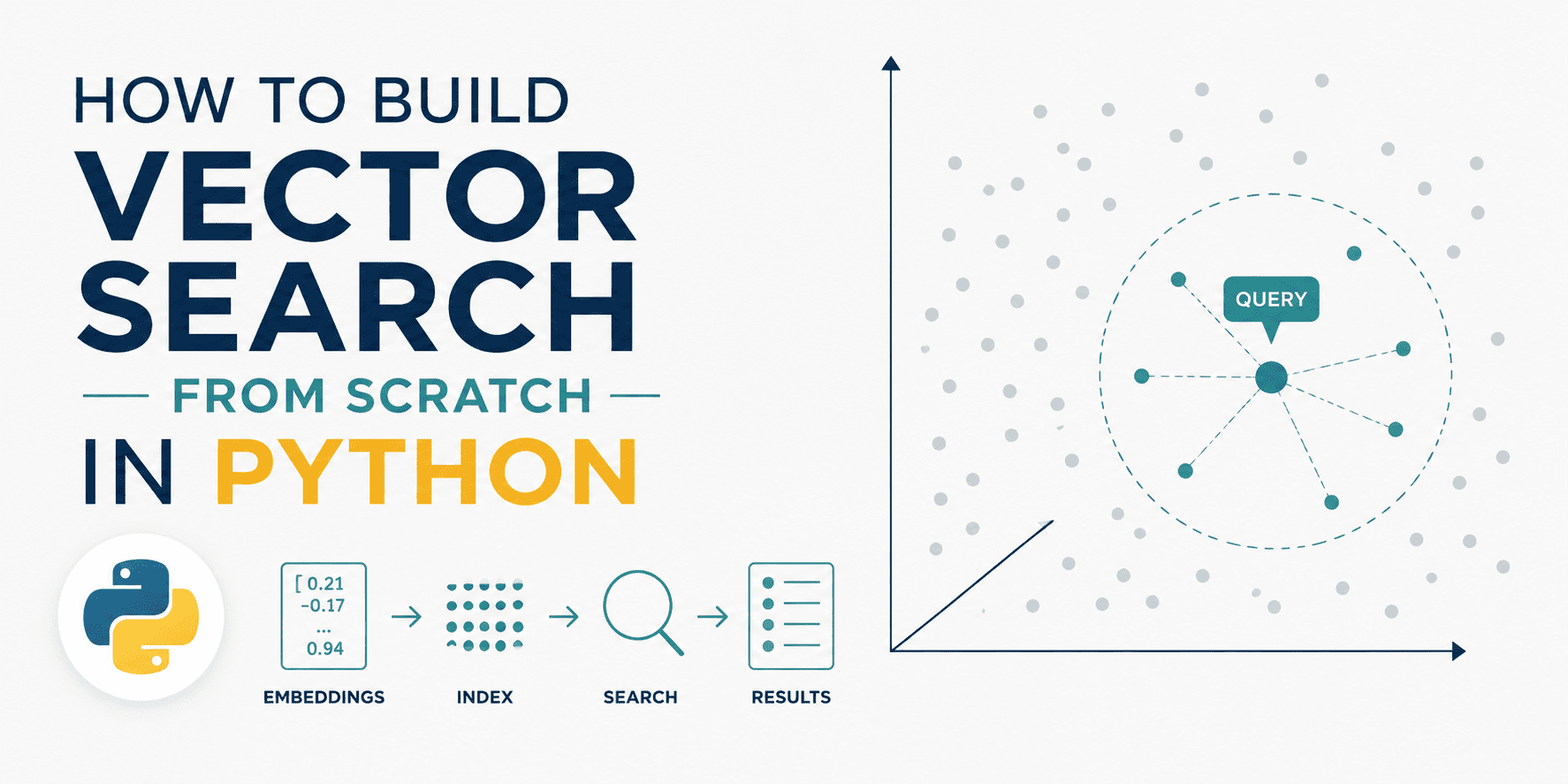
A tutorial published on KDNuggets walks through building a vector search engine from first principles using only Python and NumPy, explicitly removing the abstraction layers that most practitioners rely on. The approach uses eight-dimensional embeddings to demonstrate how documents and queries are encoded as points in semantic space, then retrieved through cosine similarity—the distance metric that connects geometric proximity to meaning. By implementing each step directly rather than delegating to a managed service, the exercise exposes what actually happens inside the vector databases that have become foundational to modern AI infrastructure: how embeddings are stored, normalized, and compared to surface semantically relevant results rather than mere keyword matches.
Vector search has moved from a research curiosity to a critical component of the AI stack almost overnight, driven by the explosive adoption of large language models and retrieval-augmented generation. Yet this transition happened largely behind closed doors—most developers interact with vector search through managed services like Pinecone, Weaviate, or Milvus, treating the internals as an opaque black box. The gap between adoption and understanding is real and expanding: companies ship products that depend entirely on semantic search without anyone on their team truly grasping what "cosine similarity" means or why it matters. Educational content that fills this gap arrives at a moment when the infrastructure has already scaled, leaving a cohort of practitioners who can operate these systems but cannot reason about their fundamental limitations.
The significance lies not in the technical novelty—vector search itself is decades old—but in the democratization of understanding. When developers grasp that semantic search is just a geometry problem, that cosine similarity reduces to a dot product, and that clustering happens naturally in the embedding space, they gain the ability to diagnose failures, optimize performance, and make informed choices about which tools to adopt. This moves the AI industry toward a healthier state where infrastructure decisions are grounded in fundamentals rather than marketing narratives. Companies building on vector search will make better architectural choices if their teams understand the tradeoffs between different similarity metrics, embedding dimensions, and quantization strategies. The tutorial effectively raises the floor for technical competence in this increasingly critical domain.
This matters most to machine learning engineers and data scientists actively building production systems who operate without deep infrastructure knowledge, and to organizations evaluating whether to invest in a vector database platform or build search capabilities themselves. Teams deploying RAG systems, recommendation engines, or semantic search stand to benefit immediately from understanding how their chosen infrastructure actually works. Equally important are the students and junior engineers learning AI infrastructure for the first time—hands-on tutorials that avoid premature abstraction shape how they think about problems years into their careers. Smaller companies and startups operating on tight budgets may also find value in determining whether they truly need a managed service or can build sufficient functionality in-house.
The competitive dynamics around vector databases are more nuanced than the educational content might suggest. Services like Pinecone and Weaviate could perceive this as a threat, but the effect may ultimately benefit them. More sophisticated demand from practitioners who understand the underlying technology tends to expand adoption rather than suppress it—customers who know what they're doing are actually more likely to invest in professional-grade infrastructure because they can identify specific needs the DIY approach cannot satisfy. The real competitive pressure comes from cloud providers rolling vector search into existing databases (Postgres with pgvector, MySQL with vector support) rather than from educational tutorials. That said, deep familiarity with the mechanics can push developers toward custom solutions when their use case is specialized enough to justify it.
The trajectory to watch involves whether this educational movement accelerates and whether it actually changes how practitioners approach vector infrastructure decisions. If similar tutorials proliferate across major platforms—expanding beyond the basics to cover approximate nearest neighbor search, quantization, and distributed systems—the industry gains a foundation for more sophisticated conversations about tradeoffs and optimization. The risk is that fundamental understanding remains siloed among researchers and infrastructure specialists while most practitioners continue operating tools they don't fully comprehend. Another open question is whether managed service providers will lean into education as a competitive lever, sponsoring or producing advanced tutorials that deepen customer expertise. The next phase will reveal whether vector search matures into a well-understood primitive that most teams can reason about, or remains a black box that only specialists navigate with confidence.
This article was originally published on KDNuggets. Read the full piece at the source.
Read full article on KDNuggets →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to KDNuggets. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.




