
Ben's Bites
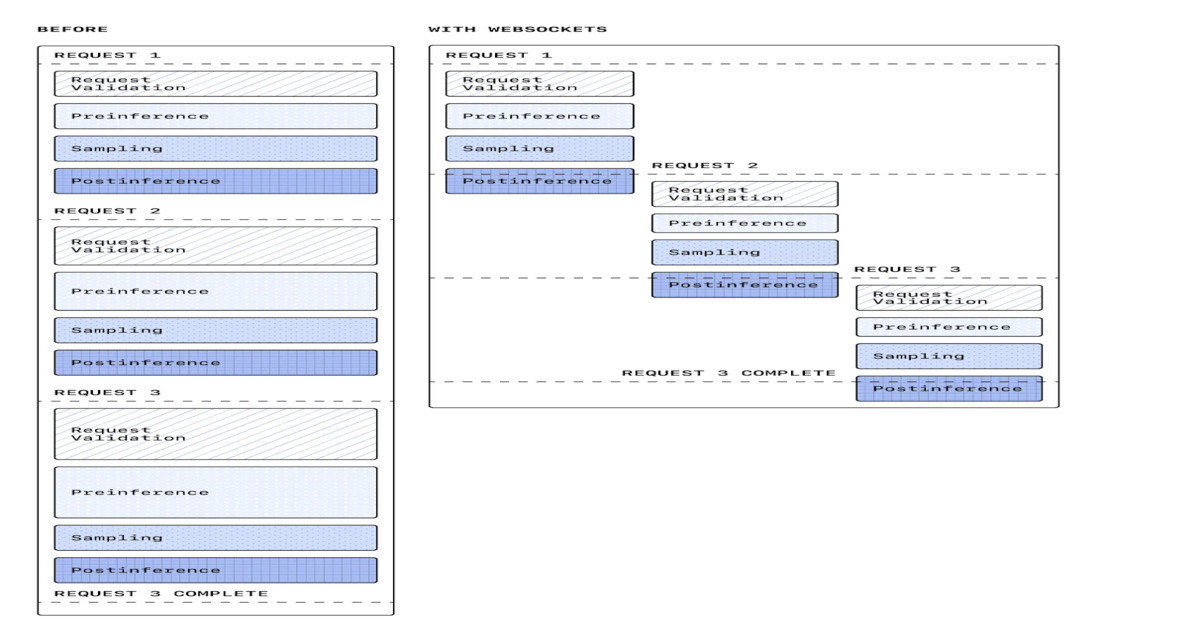
OpenAI has rolled out a WebSocket-based execution mode for its Responses API, swapping the conventional request-response pattern for a persistent bidirectional channel built specifically for agentic workloads. The company is reporting up to 40 percent reductions in end-to-end latency in early production deployments, with sustained throughput near 1,000 transactions per second and burst capacity reaching 4,000 TPS. The mechanics are straightforward: instead of opening a fresh HTTP connection for every reasoning step, tool invocation, or follow-up query, agents now maintain a single warm session that carries state across the entire workflow. OpenAI engineer Gabriel Chua noted the connection can be primed by front-loading system prompts and tool definitions, and confirmed compatibility with Zero Data Retention deployments. Vercel, Cursor, and Cline have already integrated the mode into their developer tooling, each reporting gains in the 30 to 40 percent range on multi-step coding workflows.
The timing here is not coincidental. Over the past eighteen months, raw inference latency has fallen dramatically thanks to faster hardware, speculative decoding, and smaller distilled models, which has had the paradoxical effect of exposing transport overhead as the new bottleneck. When a single forward pass takes 200 milliseconds and the TLS handshake plus HTTP framing takes another 150, the network suddenly accounts for nearly half of perceived response time. Agent frameworks compound the problem because they chain dozens of these round trips together, with each tool call, planning step, and reflection burning the same setup cost. The industry has been quietly converging on this realization for months, with projects like the Model Context Protocol and various streaming SSE patterns gesturing at the same problem from different angles. OpenAI is simply the first major lab to ship a transport-layer answer at scale.
What makes this announcement consequential is less the technology itself — WebSockets have been industrial infrastructure for over a decade — and more what it signals about where the frontier of AI engineering is moving. The marginal returns on pure model intelligence are getting harder to extract, but the systems wrapped around those models remain shockingly primitive. Treating an agent loop as a sequence of stateless API calls was always an artifact of how chat completion endpoints evolved, not a principled design choice. By formally embracing persistent sessions, OpenAI is admitting that the unit of interaction is no longer a prompt-response pair but a stateful collaboration, and the API surface should reflect that. This is the kind of plumbing decision that quietly resets baselines for the entire ecosystem.
For developers building coding agents and autonomous tooling, the practical impact lands almost immediately, since the migration cost is low and the latency budget freed up can be reinvested in deeper reasoning chains or more aggressive tool fan-out. Enterprise architects gain something subtler but more valuable: state-carrying sessions simplify observability, make backpressure tractable, and align AI traffic with the event-driven patterns their platform teams already understand. Researchers focused on multi-agent coordination get a primitive that finally matches their mental model, where conversations between models or between models and tools no longer have to be reassembled from disconnected request fragments. End users will notice none of this directly, but they will feel it in coding assistants that finish suggestions before context evaporates and in voice agents that stop sounding like they are dialing in over satellite.
Competitively, this puts pressure on Anthropic, Google, and the open-weights camp to clarify their own transport stories. Anthropic's streaming and tool-use APIs are robust but still fundamentally HTTP-shaped, and Google's Gemini Live has gone further on real-time audio but has not generalized the pattern to general agentic execution. Inference providers like Groq, Fireworks, and Together have leaned hard on raw token speed but generally defer transport semantics to the framework layer, which now looks like a gap rather than a feature. Expect a wave of WebSocket and gRPC-streaming variants from competitors within the next two quarters, along with renewed interest in standards bodies trying to prevent another fragmentation episode like the early days of function calling.
The questions worth tracking are operational rather than architectural. Persistent connections create new failure modes around session affinity, graceful degradation during model rollouts, and load balancing across heterogeneous GPU pools, and OpenAI has not yet published much about how it handles these at scale. There are also unresolved implications for billing transparency, since long-lived sessions blur the boundary between discrete API calls and continuous compute. The deeper question is whether this is a transitional optimization or the first move toward a fundamentally different agent runtime, one where the model, tools, and orchestration logic share a colocated execution environment rather than communicating across a public network at all.
This article was originally published on InfoQ AI. Read the full piece at the source.
Read full article on InfoQ AI →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to InfoQ AI. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.




