
🤗 AI Labs
Hugging Face Blog
6 min read
Your hub for Benchmarking news and research — curated daily from 50 top AI sources including OpenAI, Anthropic, Google DeepMind, and more. Every article is reviewed and enriched with editorial analysis by the DeepTrendLab team.

Welcome to Import AI, a newsletter about AI research. Import AI runs on arXiv and feedback from readers. If you’d like to support this, please subscribe. A shorter issue than…

Welcome to Import AI, a newsletter about AI research. Import AI runs on arXiv and feedback from readers. If you’d like to support this, please subscribe. Subscribe now Can LLMs…
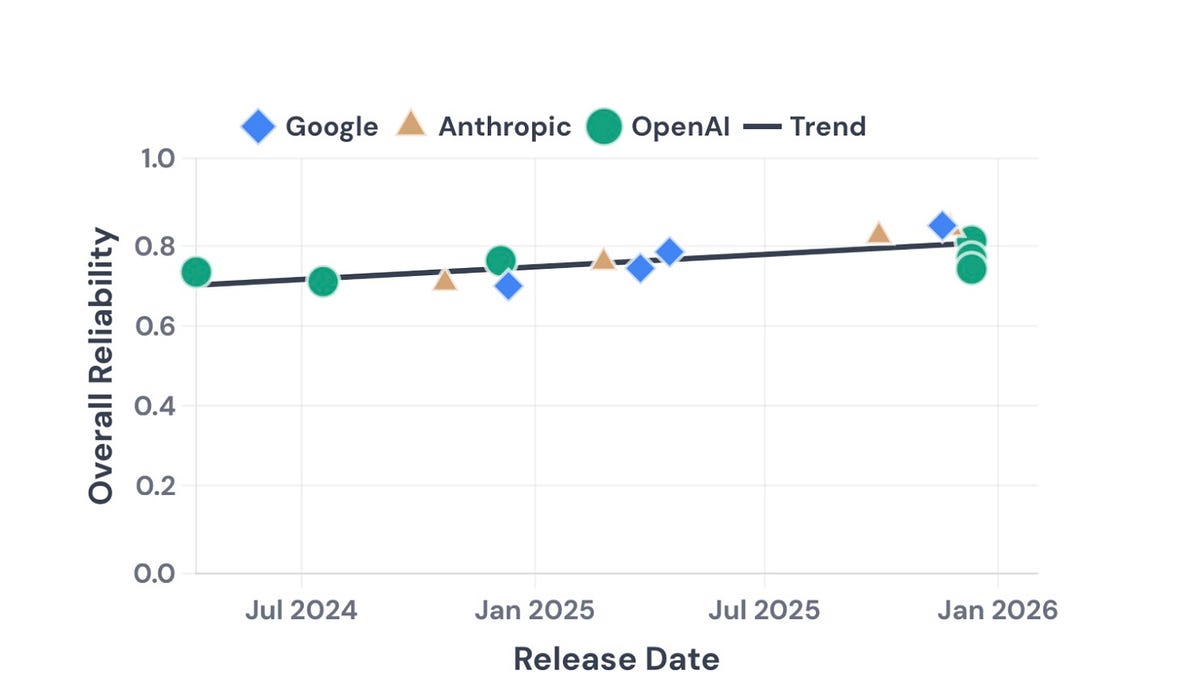
Quantifying the capability-reliability gap

Welcome to Import AI, a newsletter about AI research. Import AI runs on arXiv and feedback from readers. If you’d like to support this, please subscribe. Subscribe now Want to…
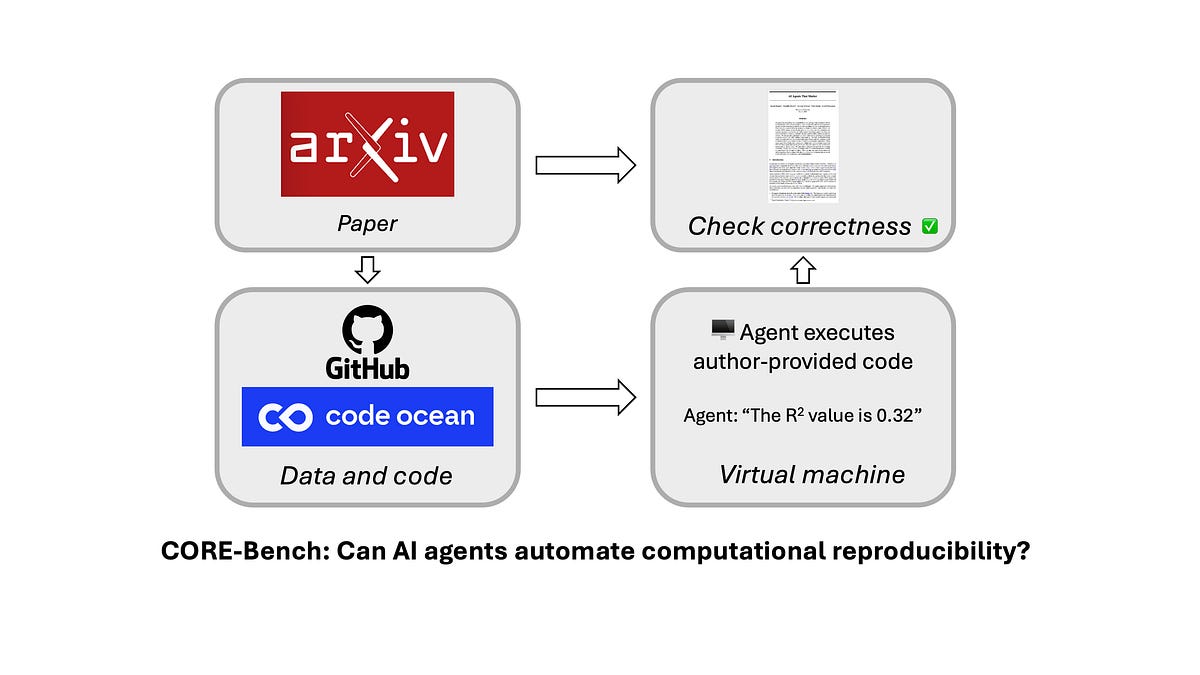
A new benchmark to measure the impact of AI on improving science

Rethinking AI agent benchmarking and evaluation
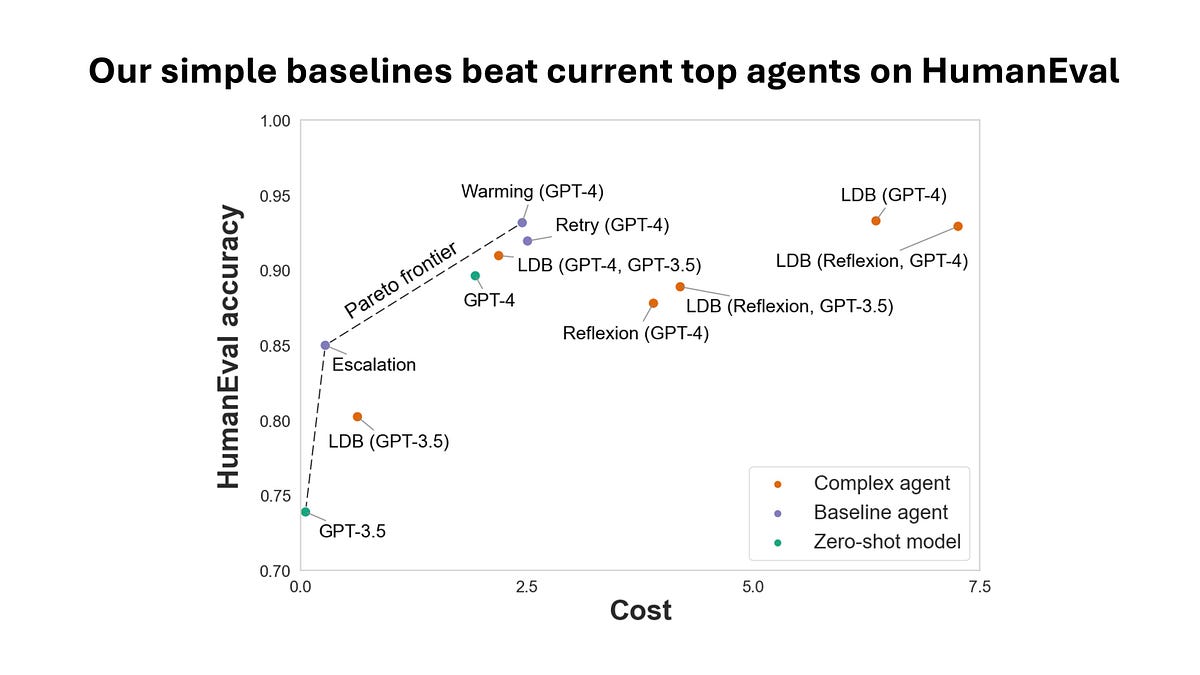
What spending $2,000 can tell us about evaluating AI agents