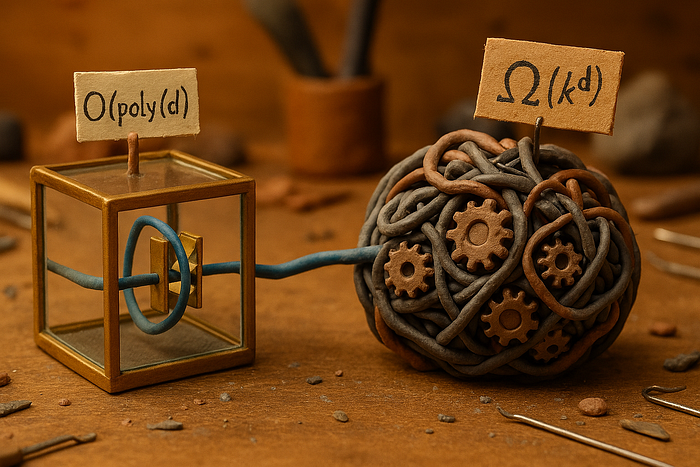
Computer science research has just formalized something practitioners sensed but couldn't quite measure: the modern obsession with transformer architectures rests on a computational privilege that RNNs cannot match. A paper awarded Outstanding Paper at ICLR 2026, "Transformers are Inherently Succinct," establishes that while recurrent neural networks possess the theoretical ability to express functions identical to transformers, they pay an exponential cost in parameter count to do so. The distinction matters because it reframes a decade of architecture debates from pure capability (can RNNs do it?) to economic reality (can RNNs do it without doubling their weight?). The research zeroes in on compositional depth—tasks requiring nested or hierarchical reasoning where transformers compress information efficiently while RNNs must expand their internal state geometrically. This is not a minor gap in the efficiency frontier; it is a fundamental architectural divide that has been hiding in plain sight.
The academic conversation leading to this moment reveals how research communities can ask nearly the right question and still miss the insight. For years, papers compared RNNs and transformers on benchmarks that favored shallow, linear reasoning tasks where the gap narrowed to noise. Researchers noted that RNNs theoretically could compute any transformer function and marked the question resolved. What got lost was a critical second-order query: representability without explosion. The ICLR 2026 work surfaces evidence that evaluation protocols themselves had become blindspots—studies measured perplexity and accuracy while overlooking the hidden cost curves in parameter budgets as nesting depth increased. This happened because parameter efficiency was not yet a pressing constraint when these comparative studies began, and by the time efficiency became economically critical, the research narrative had already settled on a winner. The paper essentially asks the community to look at its own data again, but this time with cost as a visible dimension.
The implications stretch from immediate practical concerns to how the field designs future architectures. In an era of multi-billion-parameter models, every doubling of required parameters translates to doubled training time, storage, and inference latency. For organizations deploying models at scale—inference-heavy applications, edge devices, real-time systems—this exponential penalty is not theoretical; it is a budget line item. The finding also recalibrates what "model selection" actually means; the choice between RNNs and transformers is no longer "can I solve this?" but "what is my parameter budget for this class of problem?" This distinction opens a design space that the field had effectively foreclosed by assuming transformers were universally superior. For researchers, it signals that succinct representations matter as much as universal expressivity, potentially redirecting effort away from architecture arms races toward understanding why certain inductive biases let some models compress information that others must expand.
The research lands most immediately on researchers and engineers responsible for architecture selection in resource-constrained settings. Edge ML practitioners, mobile teams, and anyone deploying on devices without datacenter budgets suddenly have a sharper metric for understanding why their RNN experiments failed: not because RNNs lack capability, but because the parameter cost exploded at compositional depths their applications demanded. For large organizations running inference at scale, the work validates the economic logic of transformer adoption while also suggesting that hybrid systems—using RNNs for linear sequence processing and transformers only for branches requiring deep composition—might reduce total parameter footprint. For the broader ML community, it is a cautionary reminder that practitioners have been using benchmarks optimized for transformer strengths; the paper implicitly argues that fairer evaluation would show RNNs not missing ability but paying rent in different currency.
Competitive pressures in ML have created a landscape where transformer-centric claims enjoy asymmetric credibility. Funding, talent, and infrastructure investments all flowed toward transformer scaling partly because the architecture seemed to dominate empirically. This paper introduces asymmetry in the opposite direction: transformers are superior, yes, but only if you can afford them. For smaller teams, research institutions without GPU budgets, and companies building for latency-sensitive applications, RNNs or hybrid alternatives suddenly become more rationally defensible. The work may also accelerate interest in architectural innovations that split tasks—using lightweight sequential models for foreground tasks and sparse transformer layers for compositional reasoning. It fundamentally changes the narrative from "transformers won" to "transformers excel in high-budget regimes; everything else depends on your constraints."
The open questions now concern evaluation methodology and hybrid design. Will the community rebuild its benchmarks to make parameter-to-performance tradeoffs visible rather than hidden? Will the efficiency awareness this paper creates lead to renewed investment in RNN variants, attention mechanisms that require fewer parameters, or truly hybrid systems that use multiple architectures collaboratively? The most intriguing possibility is that this research will precipitate a broader recalibration of how researchers report findings—not just accuracy or perplexity, but the cost curves that make those metrics achievable. Watch for papers that re-evaluate past architecture comparisons through this lens, and for practical systems that consciously adopt multi-architecture strategies rather than standardizing on transformers wholesale.
This article was originally published on Towards AI. Read the full piece at the source.
Read full article on Towards AI →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to Towards AI. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.