
🤗 AI Labs
Hugging Face Blog
4 min read
Your hub for Large Language Models news and research — curated daily from 50 top AI sources including OpenAI, Anthropic, Google DeepMind, and more. Every article is reviewed and enriched with editorial analysis by the DeepTrendLab team.

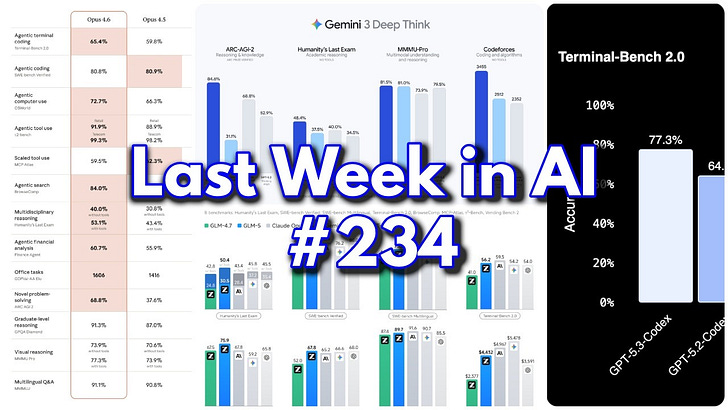
OpenAI launches GPT-5.4 with Pro and Thinking versions, Google releases Gemini 3.1 Flash Lite at 1/8th the cost of Pro, Where things stand with the Department of War Anthropic

Anthropic releases Sonnet 4.6, Google Rolls Out Gemini 3.1 Pro, Anthropic CEO Amodei says Pentagon’s threats ‘do not change our position’ on AI
An action-packed episode!
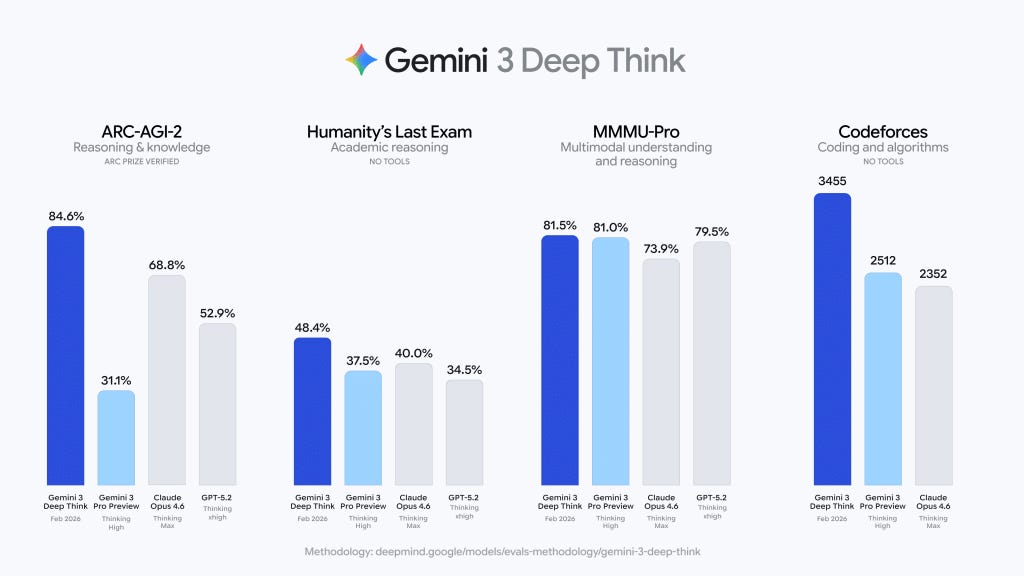
A crazy packed edition of Last Week in AI! Plus some small updates.

China’s Moonshot releases a new open source model Kimi K2.5 and a coding agent, Google Brings Genie 3’s Interactive World-Building Prototype to AI Ultra Subscribers, and more!
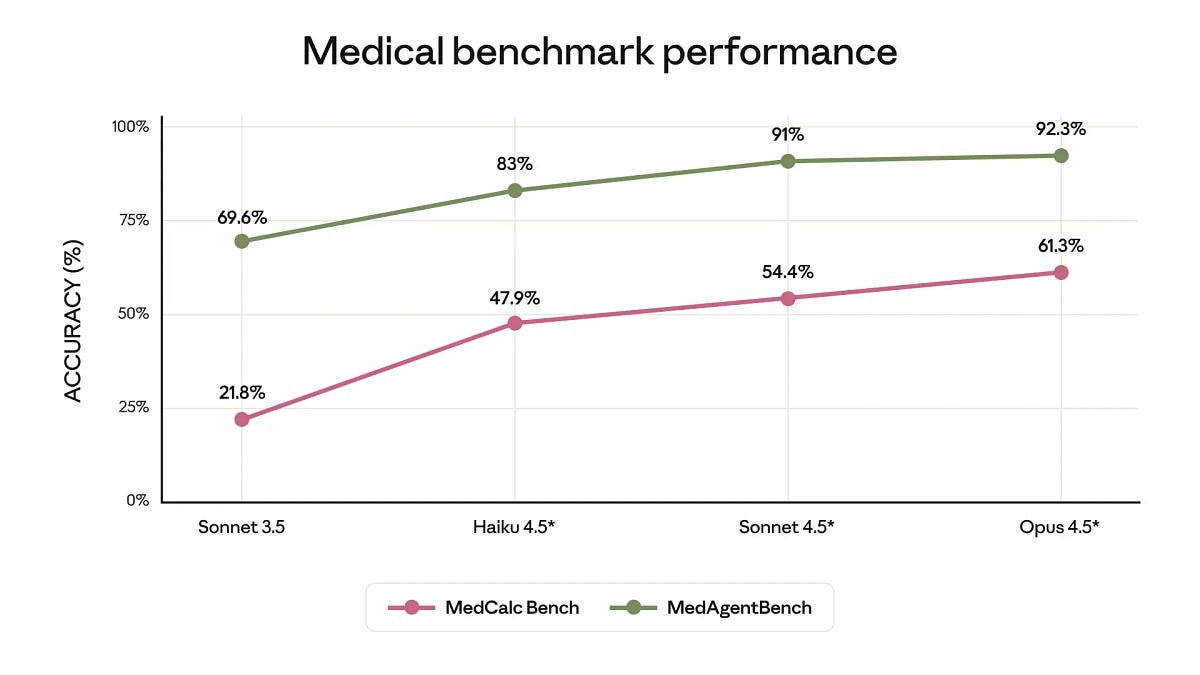
Google’s Gemini to power Apple’s AI features like Siri, OpenAI signs deal worth $10B for compute from Cerebras, and more!
MIT introduces SEAL, a framework enabling large language models to self-edit and update their weights via reinforcement learning. The post MIT Researchers Unveil “SEAL”: A New Step Towards Self-Improving AI…

A newly released 14-page technical paper from the team behind DeepSeek-V3, with DeepSeek CEO Wenfeng Liang as a co-author, sheds light on the “Scaling Challenges and Reflections on Hardware for…

DeepSeek AI releases DeepSeek-Prover-V2, an open-source LLM for Lean 4 theorem proving. It uses recursive proof search with DeepSeek-V3 for training data and reinforcement learning, achieving top results on MiniF2F.…

Kwai AI's SRPO framework slashes LLM RL post-training steps by 90% while matching DeepSeek-R1 performance in math and code. This two-stage RL approach with history resampling overcomes GRPO limitations. The…

DeepSeek AI, a prominent player in the large language model arena, has recently published a research paper detailing a new technique aimed at enhancing the scalability of general reward models…

Every week there’s a better AI model that gives better answers. But a lot of questions don’t have better answers, only ‘right’ answers, and these models can’t do that. So…

Powerful AI agents are about to hit the market. Here we explore the implications.

Exploring the utility of large language models in autonomous driving: Can they be trusted for self-driving cars, and what are the key challenges?