AWS Machine Learning Blog

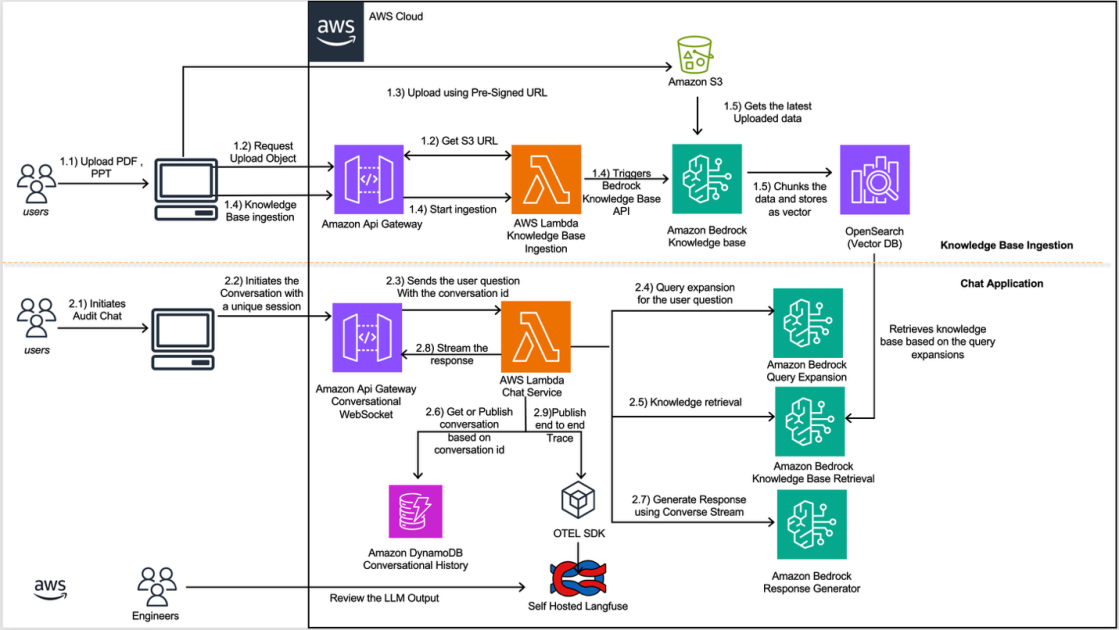
AWS and Pulse AI have jointly demonstrated a system for processing financial documents that combines vision language models with classical machine learning infrastructure through Amazon Bedrock. The headline result is striking: a batch of 1,000 complex financial documents that historically required days of manual handling was processed in under three hours, yielding structured, audit-ready outputs. This isn't a simple OCR upgrade. Instead, it represents a convergence of two shifts in enterprise AI—the move from treating documents as pixel arrays to understanding them as structured semantic objects, and the shift from proprietary, monolithic tooling to modular, cloud-managed infrastructure.
Financial document processing has long been a pain point precisely because the complexity of these materials exceeds what traditional OCR can handle. A balance sheet isn't just text; it's a network of relationships where merged cells, multi-column layouts, and hierarchical references embed meaning that pure image-to-text systems routinely miss. When those errors propagate—when a misread figure in one cell cascades through dependent calculations—the cost to financial organizations multiplies rapidly. The emergence of capable vision language models created an opening, but deploying them at enterprise scale required solving the infrastructure puzzle: ML operations, model fine-tuning, deployment logistics. Bedrock addresses this by offering fully managed model customization without the operational tax that traditionally accompanied such work.
What matters here is the economics becoming rational for a much broader class of organizations. Document extraction has never been a cheap problem, but the traditional cost structure—hiring specialized teams, managing infrastructure, dealing with model drift—put sophisticated solutions out of reach for all but the largest players. When processing 1,000 documents became a days-long project, many organizations accepted the cost as unavoidable friction. Now the equation shifts. The same workload takes hours. Bedrock's model does not require capacity planning or dedicated machine learning staff. Custom fine-tuning on domain-specific data becomes feasible rather than theoretical. This reframes document processing from a cost center to a solvable operational problem, which changes what kinds of automation become worthwhile.
The immediate beneficiaries are financial institutions and any organization processing high volumes of complex documents—auditors, regulatory bodies, insurance companies, private equity. But the pattern extends further. Developers building enterprise applications now have access to document understanding as a managed service, eliminating the need for deep expertise in machine learning operations. Organizations in adjacent domains with similar structural complexity—legal contracts, medical records, technical specifications—see a proven playbook they can adapt. The shift creates a tier of builders who can deploy document AI without being machine learning engineers themselves.
This announcement is also a statement about cloud strategy. AWS is positioning Bedrock as the infrastructure backbone for enterprises adopting AI at scale, emphasizing managed customization and cost-per-inference over raw model capability. This competes not just with other foundation model providers but with the entire premise that organizations should operate their own machine learning infrastructure. By bundling extraction, fine-tuning, and deployment into a unified managed service, AWS is betting that enterprises will choose friction-free integration over bare-metal alternatives. The approach also emphasizes data residency and compliance—financial institutions can process sensitive documents without shipping data to third-party model providers.
Several tensions and questions loom. Regulatory scrutiny of AI-extracted financial data remains largely unwritten; financial authorities have not yet established benchmarks for what accuracy rates satisfy audit requirements. The cost economics work at scale, but edge cases and adversarial documents may still require manual handling, complicating the total-cost-of-ownership calculation. Competitors will inevitably offer similar managed document processing, and whether AWS's implementation proves superior remains an open question. Most intriguingly, this pattern—structure extraction, semantic understanding, domain-specific fine-tuning—will likely spread to other complex document categories, turning financial document processing from a specific problem into a template for how enterprises approach unstructured data at scale.
This article was originally published on AWS Machine Learning Blog. Read the full piece at the source.
Read full article on AWS Machine Learning Blog →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to AWS Machine Learning Blog. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.




