AWS Machine Learning Blog

Miro has quietly solved one of software engineering's persistent friction points: the problem of miscategorizing bugs in organizations with hundreds of teams. Through a partnership with AWS, the 95-million-user workspace company built BugManager, an AI system powered by Amazon Bedrock that automatically routes bug reports to the correct team. The results are stark enough to reshape how we think about large-scale software triage: six times fewer team reassignments and five times faster time-to-resolution compared to their previous system. The breakthrough reveals not just a local win for Miro but a fundamental shift in how enterprises should approach labor-intensive classification problems when traditional machine learning hits its limits.
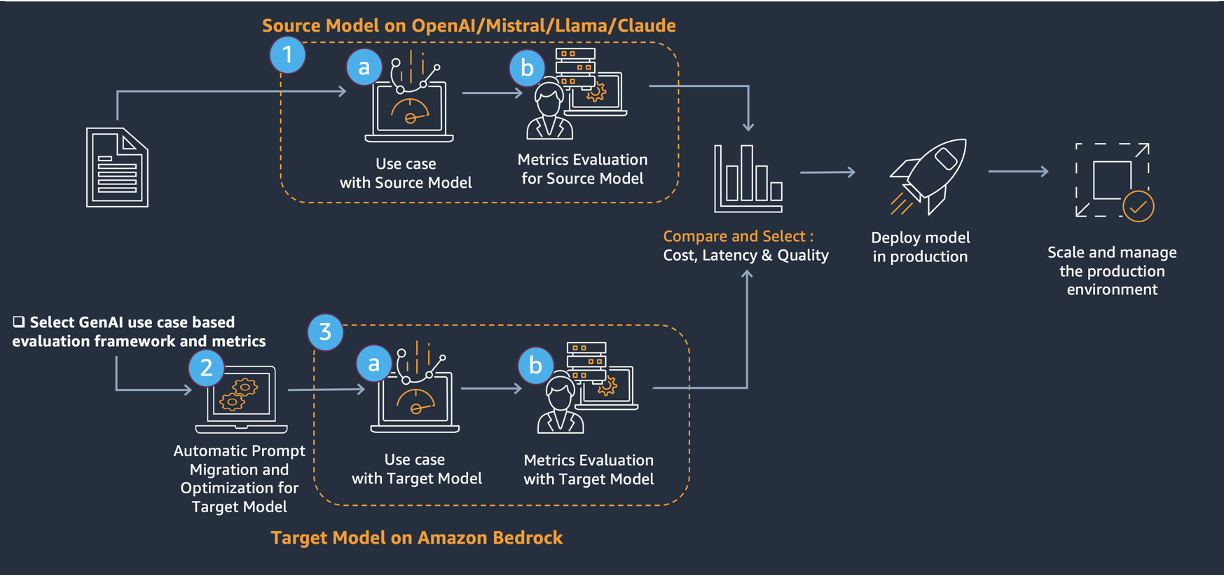
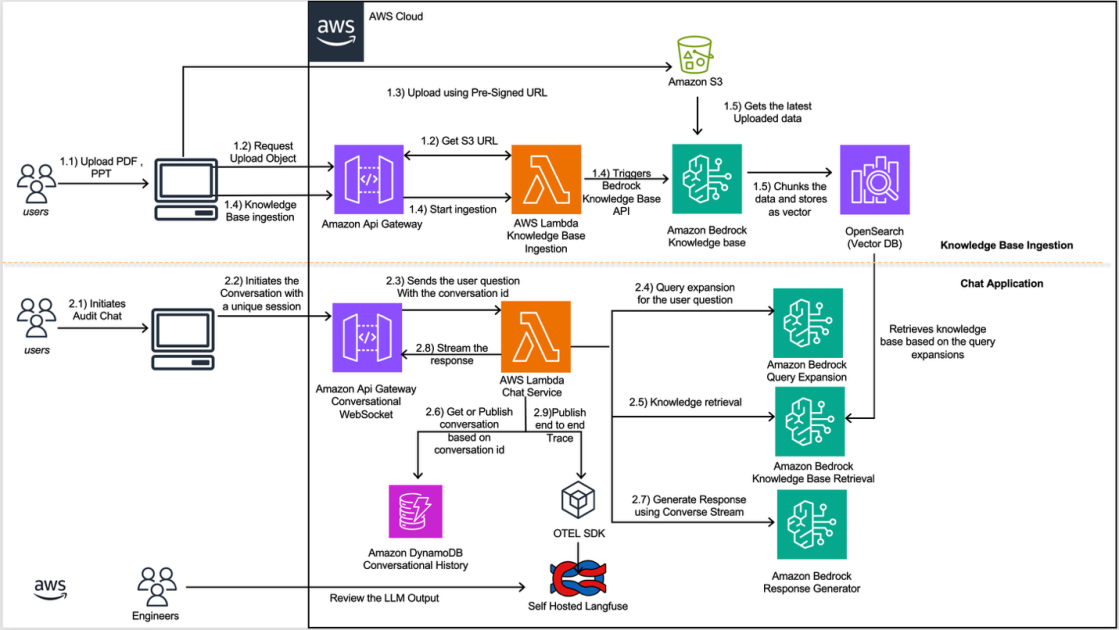
The context here is revealing. Bug routing at scale is messier than traditional machine learning can handle. Reports arrive as garbage—incomplete text, stack traces, video, screenshots, context scattered across GitHub, Confluence, and corporate memory. Meanwhile, the organizations themselves are moving targets: teams merge, responsibilities shift, products evolve. Miro's earlier attempt at a fine-tuned GPT classifier degraded rapidly as the organizational topology changed, because the system had to be retrained every time the organizational chart shifted. The problem wasn't a lack of ML sophistication; it was that the underlying world was too dynamic for supervised approaches to keep pace. Traditional NLP and fine-tuned classifiers assume a relatively stable classification problem. In reality, bug routing is a problem that mutates constantly.
This matters because it reveals when and why large language models actually outperform engineered machine learning. The shift from fine-tuning to prompt optimization represents a real departure from the last decade of enterprise AI. Where supervised learning demanded clean data pipelines and retraining cycles, prompt-based classification adapts immediately to organizational changes by simply updating context in the prompt itself—new teams, new product features, new documentation. There's no retraining, no data collection bottleneck, no week-long lag waiting for new labels. Miro's success suggests that for problems living in fluid environments, the foundation model approach with good prompting discipline beats custom-trained models by an order of magnitude.
For developers and engineering organizations, this has immediate practical implications. Bugs that get misrouted are invisible productivity drains: context-switching costs, frustration, delayed fixes, customer impact cascading from poor triage. Organizations with fifty teams, five hundred teams, or more face this problem acutely. Miro's results—cutting resolution time by 80 percent—aren't trivial engineering gains; they're the difference between a team shipping fast and a team trapped in coordination overhead. For enterprises with sprawling engineering organizations, this pattern (prompt-optimized classification replacing fine-tuned models) offers a template that could apply across hiring, incident response, content moderation, and any high-volume classification task where the schema itself changes faster than models can retrain.
From a competitive angle, this validates Amazon Bedrock's positioning in the enterprise AI stack. Rather than building yet another proprietary model, AWS is winning by offering friction-free access to frontier models with the operational simplicity enterprises actually need. Miro didn't need to own or fine-tune a model; they needed to ship a solution in weeks, not months. Bedrock's value lies in removing the "should we build or buy" decision by offering a clean API to models that work out of the box. This approach undercuts both the AI startup boutique model (which requires months of integration) and the open-source foundation model path (which requires operational expertise enterprises don't have). For enterprises, the real competition isn't between Claude and GPT at this point—it's between vendors who can make the technology disappear into your workflow versus those who make you manage it.
The questions emerging from this case are worth watching. First: how far does this pattern generalize? If prompt optimization beats fine-tuning for dynamic classification, do similar principles apply to other enterprise workflows? Second: what's the latency and cost envelope? Bedrock abstracts away pricing and speed, but at what scale does the prompt-heavy approach become untenable? Third: how does organizational drift actually get managed? Miro's solution still requires keeping documentation and product information in sync with prompts—that's not a solved problem, just shifted. The real story isn't that AI solved bug routing; it's that the right tool (a foundation model with context) finally made the problem tractable at the scale enterprises actually operate at. That's a template we'll see copied across the industry within the year.
This article was originally published on AWS Machine Learning Blog. Read the full piece at the source.
Read full article on AWS Machine Learning Blog →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to AWS Machine Learning Blog. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.