AWS Machine Learning Blog
Amazon Finance's regulatory response automation system represents a critical inflection point in enterprise AI deployment: the shift from experimental chatbots to mission-critical infrastructure that directly executes high-stakes business processes. Rather than using generative AI to augment human workers, this application delegates entire workflows—from document retrieval across thousands of files to response compilation within regulatory deadlines—to AI systems backed by RAG architecture and vector search. The system processes inquiries from multiple jurisdictions with different compliance frameworks, document formats, and complexity profiles, then synthesizes responses that must withstand regulatory scrutiny. This is not AI-assisted work; it is AI-as-infrastructure for a function where errors can trigger fines, legal liability, and reputational damage. Amazon is essentially betting that generative models, when grounded in reliable retrieval systems and monitored for hallucination, can become the backbone of regulatory operations at scale. That bet signals confidence that the industry has moved past the chatbot phase and into operational automation where accuracy and traceability are non-negotiable.
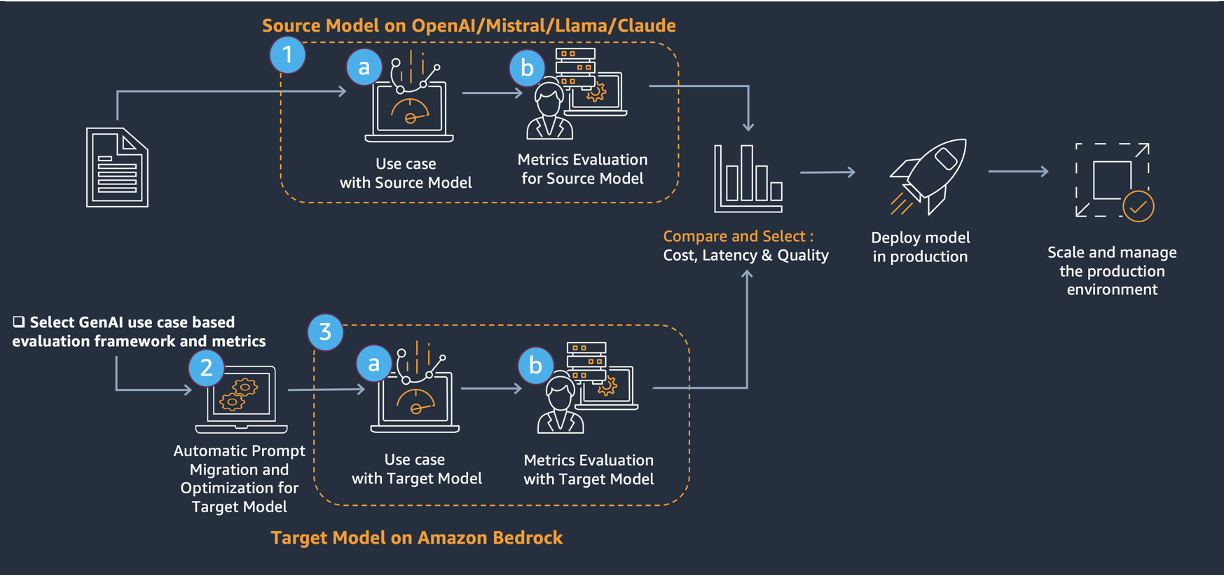
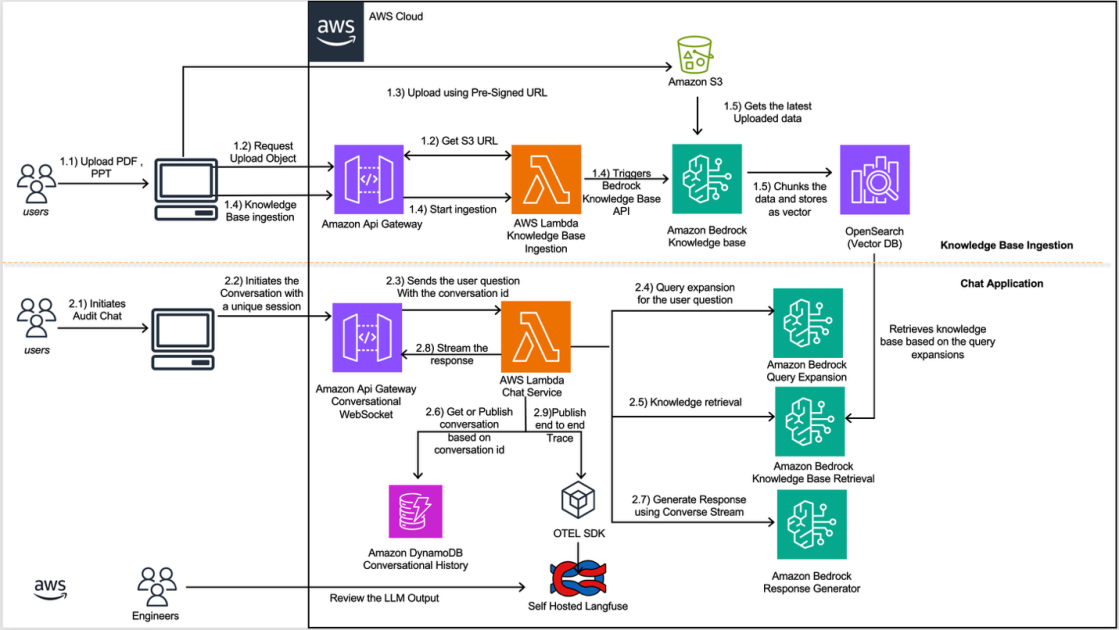
The timing reflects a convergence of three forces that make regulatory automation suddenly viable. First, large language models have matured enough that RAG systems—where the model retrieves source documents before generating responses—can anchor AI outputs to verifiable reference materials rather than leaving compliance teams at the mercy of hallucinated precedents. Second, the explosion of regulatory complexity across jurisdictions has made manual document management unsustainable; Amazon's finance teams face thousands of historical inquiries and supporting documents, a problem that scales faster than headcount. Third, the infrastructure to support this pattern has been commoditized. Amazon is using its own Bedrock service and OpenSearch Serverless, meaning the technology stack is now off-the-shelf rather than bespoke research. What was a specialized challenge two years ago—managing multi-turn conversations with regulatory context, maintaining state across sessions, detecting when models invent information—is now a recognized problem with established architectural solutions.
This system matters because it demonstrates that generative AI's real enterprise value lies not in replacing knowledge workers with cheaper alternatives, but in automating the glue work that prevents specialized teams from doing higher-value analysis. Regulatory compliance historically consumes enormous human effort on retrieval and synthesis: lawyers and analysts search through precedent, extract relevant passages, cross-reference supporting materials, and compile responses. Automating that retrieval-synthesis loop doesn't eliminate the need for regulatory expertise; it frees experts to focus on judgment calls, novel interpretation, and cases that require creative legal reasoning. The system also codifies observability as a core capability, not an afterthought. Amazon's emphasis on understanding *why* the model generated a particular response—detecting hallucinations, monitoring accuracy drift, tracking model decisions—reflects a philosophical shift in how enterprises think about AI reliability. Compliance teams need explainability not for academic rigor but for operational necessity: regulators will eventually demand to know why a particular response was generated, and "the model decided" is not a satisfactory answer.
The immediate beneficiaries are large enterprises with scale—financial services, insurance, healthcare, and regulated technology companies—where the volume of regulatory inquiries justifies investing in specialized AI infrastructure. These organizations face perpetually growing compliance burdens, and traditional solutions (hiring more compliance staff, building custom databases, training teams on every jurisdiction's unique requirements) hit hard limits. Mid-market companies and startups will benefit more gradually as the patterns mature and become easier to implement. The second beneficiary is AWS itself. This is a textbook example of AWS dogfooding: Amazon uses Bedrock and OpenSearch Serverless to solve its own operational pain point, then markets that solution to customers facing identical challenges. It gives AWS credibility that the services are production-ready, not just marketing vaporware. Smaller AI platforms and vertical SaaS vendors will also see opportunity, building specialized versions of this pattern for specific regulatory domains—healthcare compliance, financial services, pharmaceutical approval workflows.
What distinguishes this from earlier waves of enterprise AI hype is the emphasis on failure modes and guardrails. Previous announcements might have celebrated the speed of automation; Amazon's account stresses observability, hallucination detection, and continuous monitoring for accuracy drift. This reflects a maturation in the industry's understanding of where AI actually fails in high-stakes domains. The competitive implication is that enterprises will increasingly lock into vendors (AWS, Anthropic, OpenAI) not because of model quality alone, but because of the surrounding infrastructure for observability, compliance, and explainability. Generic language models become a commodity; the moat is in the tooling and the trust.
The open question is whether this pattern generalizes beyond regulatory workflows. RAG and knowledge base architecture work well for domains where the ground truth lives in documents and retrieval accuracy directly correlates with response quality. But many enterprise workflows—financial forecasting, strategic planning, customer service troubleshooting—require synthesis across unstructured data, judgment calls, and knowledge that isn't codified in documents. Amazon's regulatory system is optimized for a very specific problem: high-stakes, document-centric, low ambiguity. The next wave will determine whether similar patterns can extend into murkier domains where retrieval alone isn't sufficient and where accuracy drift is harder to detect because the right answer itself is contested.
This article was originally published on AWS Machine Learning Blog. Read the full piece at the source.
Read full article on AWS Machine Learning Blog →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to AWS Machine Learning Blog. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.