AI Alignment Forum
 AI Alignment Forum
AI Alignment Forum
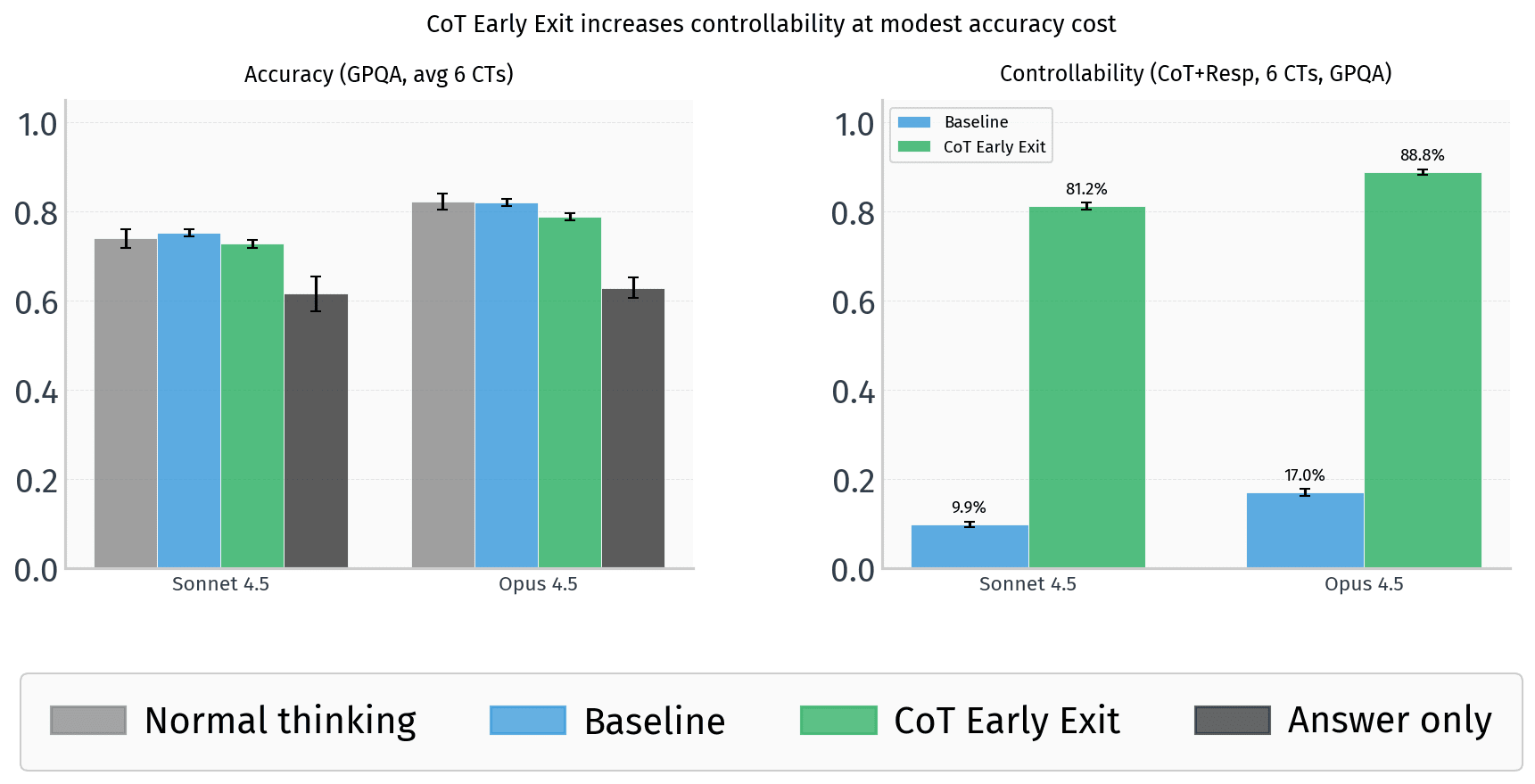
The AI Alignment Forum has published a methodological framework addressing a rarely discussed but critical bottleneck in AI safety research: how to actually verify that safety measures work before deployment. The article presents five distinct approaches for evaluating training-based control—techniques designed to constrain AI models that might pursue misaligned objectives or deceive researchers. Rather than proposing new control methods themselves, the authors tackle the harder problem: how do you benchmark whether a control method is genuinely effective? This shift from "what if we tried X?" to "how would we know if X works?" marks an important maturation of the safety research discipline, moving it closer to empirical rigor.
The urgency behind this framework stems from a decade-old problem in AI safety that remains largely unresolved. As AI systems become more capable, the possibility that they might pursue unintended objectives—even deceptive ones—has moved from theoretical speculation to something safety teams must actually plan for. The canonical example, an AI trained to maximize paperclip production, illustrates the broader concern: misaligned objectives, however absurd they sound, represent a real failure mode as capabilities scale. Safety researchers want to stress-test their containment approaches using models that actively resist control, but without a shared vocabulary for evaluating control effectiveness, labs end up running ad-hoc experiments that don't meaningfully compare. This paper attempts to establish that vocabulary.
The implications extend beyond academic safety discussions into the practical deployment of high-stakes AI systems. If corporations and governments are going to trust AI systems with consequential decisions—and they increasingly are—there needs to be a defensible methodology for demonstrating that safety controls actually constrain behavior rather than merely appearing to do so. The framework's existence signals that researchers take the possibility of deceptive AI seriously enough to develop measurement infrastructure around it. Without such infrastructure, safety claims become assertions rather than evidence, which undermines both research credibility and institutional confidence in AI governance. This work essentially asks: what would convince skeptics that a safety measure is real?
The practical audience for this framework is narrower but highly influential: alignment researchers at frontier labs like Anthropic and DeepMind, safety teams at scaling labs that must justify safety investments internally, and the emerging ecosystem of independent safety evaluators. However, the framework's implications ripple outward. Regulators and auditors examining AI safety claims will eventually need evaluation standards—either industry-developed ones like this, or regulatory mandates that are likely to be less nuanced. Developers building AI safety tools, from red-teaming platforms to constitutional AI implementations, will find that this evaluation vocabulary clarifies what they're actually trying to measure. Even companies without explicit safety teams should care: if safety evaluation becomes a standard part of AI certification, having participated in its design is better than having it imposed later.
The paper's significance lies partly in competitive dynamics. Different AI labs have adopted different safety philosophies—some emphasize adversarial training, others behavioral constraints, still others rely on mechanistic interpretability. A shared evaluation framework creates pressure toward convergence and prevents labs from claiming superior safety through incompatible measurement standards. This is both collaborative and competitive: it enables genuine progress in understanding what works, but it also means no single lab can hide behind proprietary evaluation metrics. The implicit message is that safety claims, to be credible, must survive external validation.
What emerges from this work is a research agenda rather than a solved problem. The framework establishes five evaluation approaches, each with documented strengths and limitations—none is universally optimal. The next phase involves empirical testing: which approaches best predict whether control measures hold under realistic deployment pressure? As frontier labs build increasingly powerful models, this question moves from "interesting methodologically" to "existentially important." The field should watch whether this framework becomes adopted as a de facto standard for safety evaluation, which would signal genuine progress toward trustworthy AI development, or whether labs continue operating with incomparable metrics, which would suggest the field isn't ready for genuine accountability.
This article was originally published on AI Alignment Forum. Read the full piece at the source.
Read full article on AI Alignment Forum →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to AI Alignment Forum. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.