AI Alignment Forum
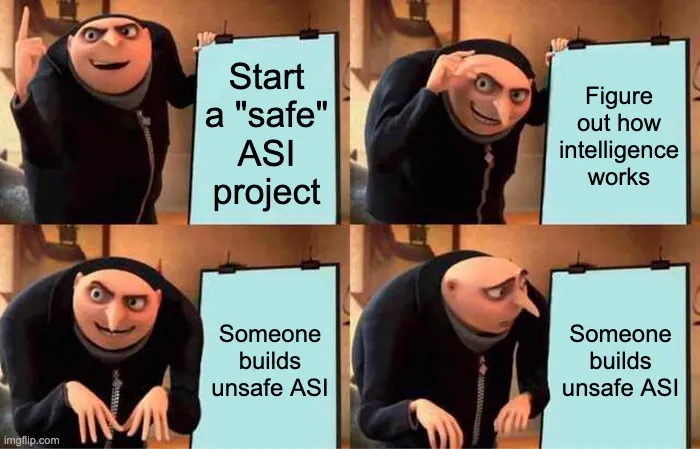
An influential post on the AI Alignment Forum has crystallized a hardening position within AI safety circles: that the conventional wisdom about "building safe superintelligence" is fundamentally misguided, and that genuine safety requires not technical solutions but geopolitical ones. The argument is stark and deliberately provocative—that meaningful AI superintelligence safety is only achievable if superintelligence development itself is globally prohibited. This framing represents a sharp departure from years of technical safety research focused on alignment, interpretability, and control mechanisms, instead pivoting toward a systems-level claim about what physical constraints actually matter.
The post emerges from a long tradition of increasingly urgent warnings within AI safety research, but it crystallizes a specific frustration: that technical approaches to "safe ASI"—whether framed as aligned superintelligence that shares human values, tool-only AI that avoids agentic behavior, or other exotic architectures—are not merely difficult but categorically impossible to guarantee. The author's dismissal of these approaches as "almost universally unworkable" reflects a growing consensus among some safety researchers that the problem space has been mischaracterized. Rather than debating whether we can align a superintelligent agent to human values (a problem with unknown difficulty), the argument shifts the question entirely: to whether development itself should proceed. This reflects a decade of compounding evidence that uncertainty in AI behavior scales faster than our ability to control it.
Why this argument matters extends beyond academic debate into real policy conversations. If safety researchers are arguing that no technical solution suffices—that attempts to build "safe" superintelligence while competition drives development forward is categorically doomed—then the entire regulatory framework being constructed around AI safety becomes unmoored from its primary goal. Current governance approaches assume that responsible development practices, testing regimes, and technical safety measures can manage existential risk. This post suggests those assumptions are false, implying that regulation focused on "safe development" is security theater. For policymakers betting on technical solutions, this is a profound challenge to their working assumptions.
The argument ripples across three distinct communities with different stakes. For AI researchers and developers, it implicitly frames their work as inadequate—no amount of alignment research or safety engineering can solve the core problem. For AI governance bodies and regulators, it suggests that their frameworks for managing AI safety through technical standards and oversight are fundamentally mistaken. For the broader AI industry, it represents an external voice arguing that superintelligence itself should not be pursued, regardless of how carefully it's approached. Each group faces a different challenge: technologists must either refute the claim or accept that their work cannot solve the problem; regulators must confront whether their mechanisms address the actual risk; and industry must grapple with calls for prohibition rather than governance.
This argument reshapes the competitive landscape by introducing a new fault line in AI governance: between those betting that technical safety can scale with capability, and those arguing it cannot. The post does not merely advocate for caution—it argues for a categorical shift in what "responsible AI development" means. If development cannot be made safe, then responsibility becomes indistinguishable from prohibition. This inverts the usual burden of proof in governance: rather than requiring proof that ASI is dangerous (which seems increasingly obvious), it argues that demonstrating safety is what should require extraordinary evidence. For companies racing toward superintelligence capabilities, this reframes the entire competitive game from "who builds the safest superintelligence" to "whether superintelligence should be built at all."
The immediate open question is whether this argument finds traction in governance conversations, or whether it remains confined to safety research communities. The framing suggests a deepening split: between researchers who believe the safety problem is solvable through better techniques, and those who see it as structurally unsolvable within competitive development dynamics. The next phase will likely involve pressure on international bodies to take the prohibition argument seriously—not as an extreme position but as the logical conclusion of decades of failed safety approaches. What remains unresolved is whether global coordination on superintelligence prohibition is more feasible than the technical safety solutions the author dismisses, a question that will define AI governance for the coming decade.
This article was originally published on AI Alignment Forum. Read the full piece at the source.
Read full article on AI Alignment Forum →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to AI Alignment Forum. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.