Towards Data Science

A practical methodology for constraining LLM output complexity has emerged as a damage-control mechanism in production systems. Researchers demonstrated that enforcing readability thresholds—using the Textstat library to cap responses at roughly a 10th-grade reading level—can be integrated into LangChain pipelines to automatically re-prompt models when outputs exceed these complexity budgets. The approach treats verbose, ornate language not as a stylistic quirk but as a measurable risk factor, triggering automatic refinement loops before responses reach users. This represents a shift from accepting LLM verbosity as inevitable to treating it as a quantifiable, correctible parameter in deployment pipelines.
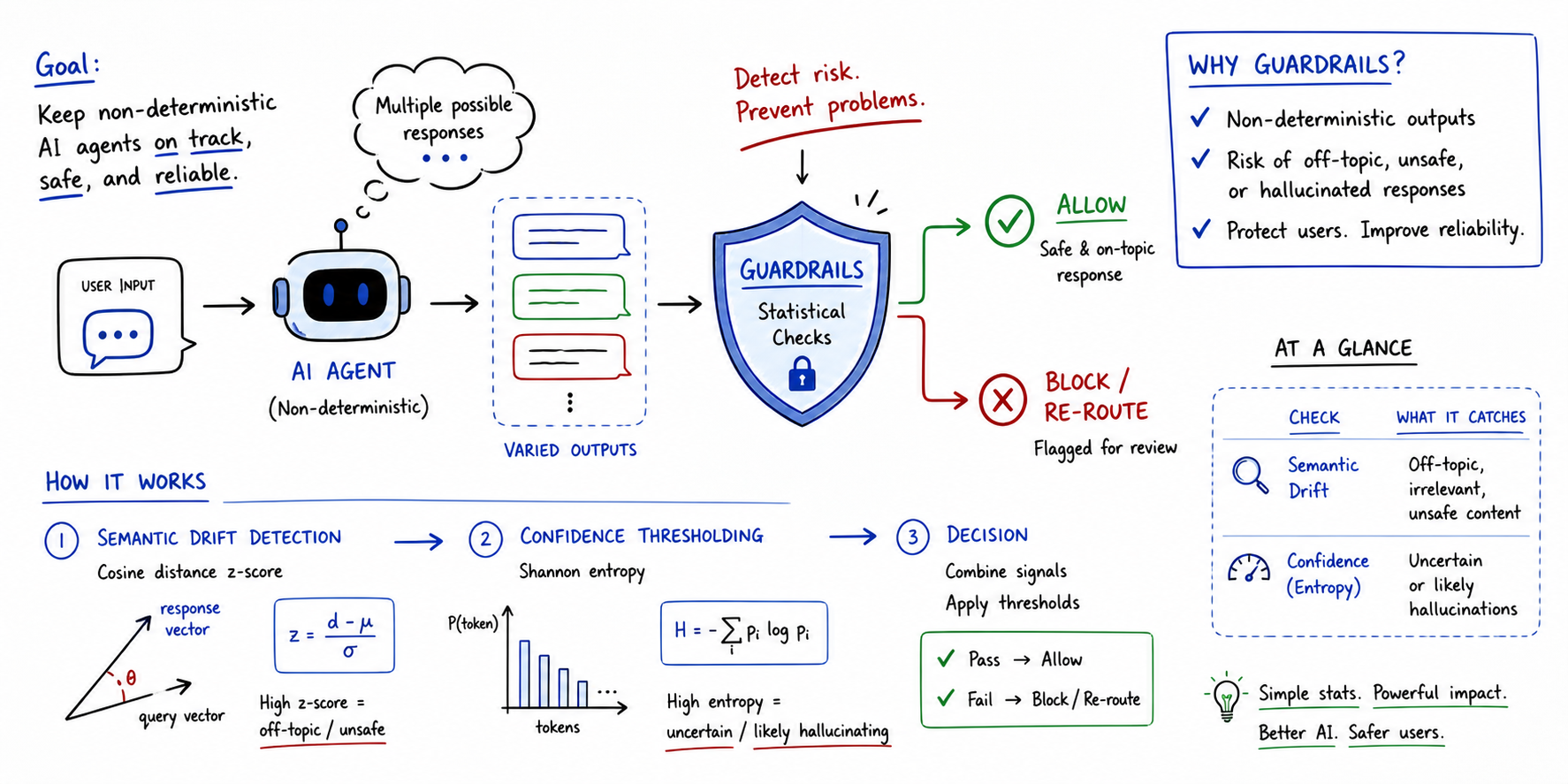
LLMs have inherent tendencies toward verbosity rooted in their training objectives. Optimized to maximize helpfulness and engagement through detailed, conversational responses, they typically generate longer outputs than necessary or optimal. Simultaneously, the field has grappled with hallucination—the generation of plausible-sounding but false information—as a fundamental limitation of these systems. The emerging hypothesis linking these two problems is straightforward: more tokens generated equals more opportunities for the model to fabricate or drift from factual grounding. This connection suggests that verbosity isn't merely an aesthetic problem but potentially a vector for unreliability, making output length a proxy metric for correctness risk.
This approach reframes a familiar LLM failure mode as an actionable engineering problem. Rather than waiting for larger models or better training to solve hallucination, it proposes an intermediate layer of quality control that can be deployed immediately. By enforcing complexity ceilings, organizations can reduce exposure to hallucination without architectural changes. More broadly, this reflects a maturing understanding that LLM reliability isn't achieved through prompting skill alone—it requires measurable, automated guardrails baked into deployment pipelines. The methodology is particularly valuable because it's language-agnostic and implementation-agnostic, capable of wrapping existing models without retraining or switching providers.
The practical impact flows directly to developers and enterprises deploying LLMs in production. Teams building chatbots, customer service systems, or knowledge retrieval pipelines face immediate pressure to reduce hallucination risk, making automated guardrails a competitive necessity rather than optional polish. Researchers studying LLM behavior gain another data point about the inverse relationship between output length and reliability. End users benefit indirectly: more constrained, readable responses reduce cognitive load while potentially improving factual accuracy. However, this creates a tiered problem—sophisticated users may prefer detailed outputs despite hallucination risk, while others demand brevity above all else, forcing organizations toward configurable complexity budgets.
This development signals a broader industry maturation around LLM deployment. The shift from "how impressive can we make the model" to "how do we make it safe and reliable in production" marks a transition from novelty to infrastructure. Organizations that operationalize hallucination detection and mitigation will gain competitive advantage in trust-critical domains—healthcare, legal, finance. Conversely, systems relying solely on prompting without guardrails risk compounding liability and regulatory exposure. Societally, this suggests LLMs may evolve toward more terse, constrained outputs as safety mechanisms, potentially changing how users interact with AI and what they expect from these systems.
The critical question is whether constraining complexity actually reduces hallucination or merely makes it less detectable. If brevity correlates with accuracy without causation, organizations may create false confidence in constrained outputs while masking underlying unreliability. Watch for emerging research quantifying the true relationship between output length and factual accuracy across different domains and tasks. Also monitor whether readability metrics alone suffice or if organizations begin layering additional guardrails—factual verification, source attribution, uncertainty quantification. Finally, consider how this shapes model development: will foundation model training begin optimizing for brevity, or will guardrails remain permanently external to model behavior, creating a permanent cat-and-mouse dynamic between base models and downstream safety layers?
This article was originally published on KDNuggets. Read the full piece at the source.
Read full article on KDNuggets →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to KDNuggets. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.