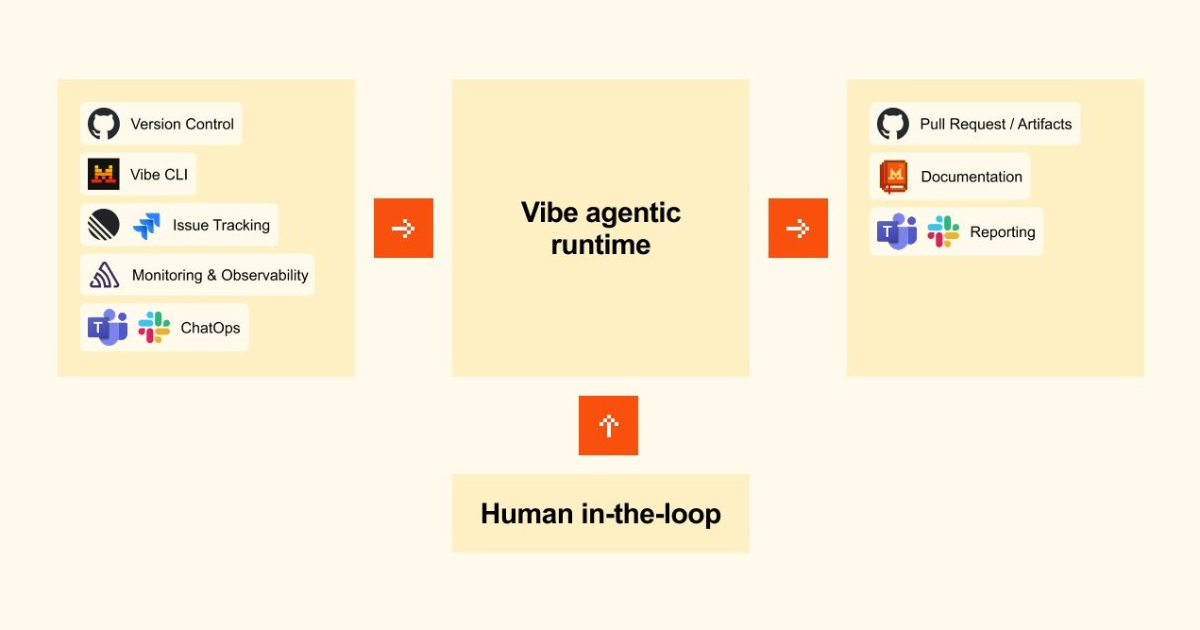
Paulo Arruda, a staff engineer at Shopify currently working on revenue data systems, offered a rare insider account of how large organizations operationalize multi-agent AI systems beyond the novelty stage. Rather than focusing on technical architecture, Arruda framed his journey as a pragmatic investigation into how engineers at scale can leverage AI without sacrificing code quality—a concern that remains largely theoretical in most enterprise settings. His particular entry point was test generation: recognizing that as AI code generation becomes more ubiquitous and developers gain confidence in its output, the burden on code reviewers intensifies dangerously. The presentation served as a case study in how one sophisticated engineering organization moved from experimenting with AI tools to building institutional safeguards around their use.
Shopify's approach to AI adoption provides useful baseline context for understanding the stakes. By 2024, the company had moved well beyond early experimentation—they had procurement relationships with all major AI providers, deployed LibreChat for agentic workflows, and ensured developers had access to Copilot and Cursor. Yet despite this infrastructure, a substantial portion of the engineering population remained skeptical or inactive, either from past friction with earlier models like GPT-3.5 or simple capacity constraints. This is the reality of enterprise AI adoption that rarely makes it into conference talks: tools alone don't guarantee adoption, and skepticism within engineering teams is often rational rather than irrational resistance. Shopify's hacker culture and explicit encouragement of experimentation created permissive conditions for innovation, but even that cultural foundation couldn't overcome the friction between productivity gains and code quality concerns.
The core insight animating Arruda's work cuts to the heart of an emerging operational problem in AI-intensive development. As AI-generated code improves incrementally, the risk isn't dramatic failures—it's the gradual erosion of review discipline. Large pull requests generated or heavily augmented by AI present reviewers with a cognitive overload; over time, reviewers develop a pattern of accepting AI contributions with less scrutiny, particularly if prior AI-assisted code proved functional. This isn't laziness; it's rational triage under resource constraints. Arruda's response—using test generation as a catch mechanism—reframes the problem from "how do we train reviewers to be more vigilant" to "how do we build systems that make low-quality code mathematically unlikely to pass." This is a shift from supervision to automation, and it's arguably the only strategy that scales.
The practitioners this directly impacts are twofold: the developers generating code and the reviewers responsible for its quality. For code-generating developers, test-generation systems represent both opportunity and constraint—the opportunity to move faster, the constraint that passing tests becomes a hard requirement rather than a soft guideline. For reviewers, the implication is more subtle: delegation of low-level quality gatekeeping to automated systems should theoretically free cognitive cycles for architectural and logic-level review. In practice, this assumes tests are comprehensive and well-designed, which is itself a non-trivial assumption. Beyond the immediate team, engineering managers and CTOs face a new class of decision: which categories of AI-generated code warrant this kind of automated testing infrastructure, and where is human review still essential?
Arruda's work highlights a competitive shift in how enterprises conceive of AI governance. Rather than treating AI tools as individual productivity multipliers that engineers adopt at their own pace, organizations like Shopify are beginning to think in terms of systemic integration—embedding safeguards and feedback mechanisms into the development pipeline itself. This is profoundly different from the "let developers choose their tools" philosophy that dominated early AI adoption. It signals maturation: companies are moving past the euphoria phase and into the harder work of operationalizing AI in ways that preserve existing quality standards. This transformation has cascading effects on developer experience, hiring criteria for code reviewers, and the technical complexity of CI/CD systems, making it a template that other large organizations are likely to replicate or adapt.
The open questions following Arruda's work are substantial. How does test-generation automation handle the coverage-completeness tradeoff—does it catch semantic errors or only syntactic ones? What happens as AI systems themselves become responsible for writing and evaluating tests, creating potential feedback loops? And perhaps most critically: does institutionalizing AI in this way entrench dependencies that lock organizations into specific providers or models? Shopify's explicit attention to building safeguards rather than merely accelerating adoption sets a template that will likely become table-stakes for enterprise AI—but whether this approach can scale beyond well-resourced engineering organizations to smaller teams or less mature codebases remains an open frontier.
This article was originally published on InfoQ AI. Read the full piece at the source.
Read full article on InfoQ AI →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to InfoQ AI. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.