AI Alignment Forum

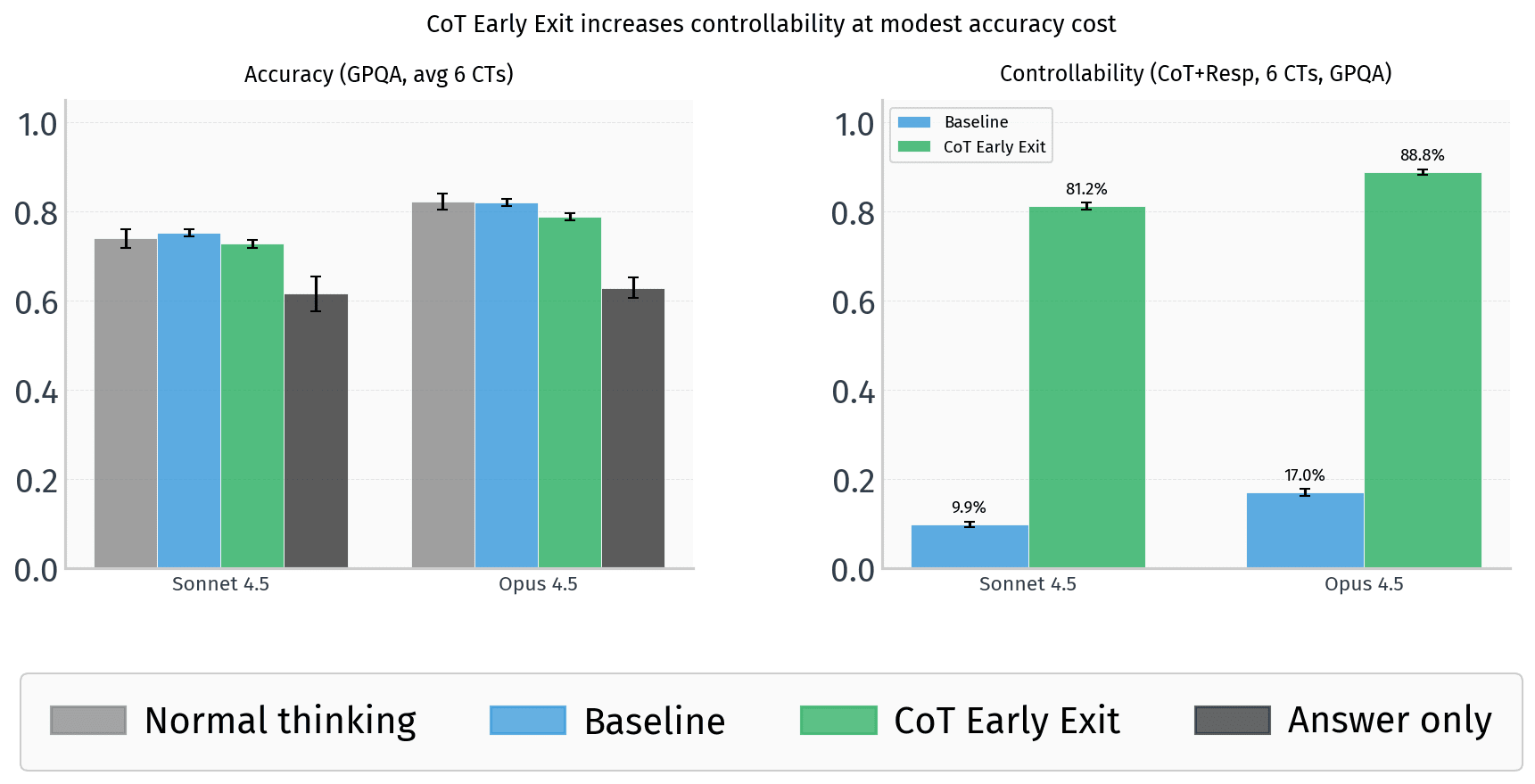
Anthropic disclosed that it accidentally corrupted the training data for Claude Mythos Preview in approximately 8% of training runs—specifically, the model's chain-of-thought reasoning was exposed to the same evaluation mechanism meant to assess only its final outputs. The company appears to have discovered the issue after the fact and characterizes it as a process failure. Notably, this marks the second separate incident in which Anthropic inadvertently compromised the integrity of a model's reasoning trace during training. The disclosure came from the AI Alignment Forum, suggesting internal concern serious enough to warrant public acknowledgment despite the reputational risk.
The context here matters enormously. Anthropic has built its brand identity on safety-first engineering, positioning itself as the responsible alternative to competitors willing to race toward greater capability with minimal guardrails. This operating model requires not just good intentions but exemplary execution—the company's entire value proposition to enterprises and regulators hinges on operational discipline that outsider observers can trust. Simultaneously, the industry is experiencing a phase transition: training runs are becoming so large and complex that human oversight is increasingly strained. The tension between scaling speed and maintaining control is becoming visceral, and Anthropic's stumble suggests that even organizations prioritizing safety are beginning to struggle with basic process integrity as systems grow larger.
Why this matters extends beyond corporate embarrassment. The chain of thought has become a cornerstone of modern AI safety research—it's the closest thing we have to a window into model reasoning, and theoretically, a mechanism for detecting deceptive or misaligned behavior. When the training process itself corrupts that signal, you're poisoning one of the few tools available for meaningful human oversight. More critically, the article notes that this weakens confidence in whether a model's reasoning is genuinely transparent or merely shaped by training pressure. In systems many orders of magnitude more capable than current models, this kind of process failure could carry existential consequences. The issue is not merely that an error occurred, but that it occurred twice, suggesting systemic rather than isolated problems.
The immediate impact ripples across three constituencies. Enterprise customers evaluating Claude for sensitive applications now face uncertainty about the integrity of the model's reasoning traces—a key selling point for safety-conscious adopters. AI safety researchers lose confidence in one of their primary tools for understanding model cognition; if the training process can't reliably preserve reasoning integrity, research built on that foundation becomes questionable. And Anthropic itself confronts a credibility deficit at precisely the moment when its safety positioning is most valuable to the organization's market differentiation and policy influence.
This incident illuminates a competitive vulnerability. Anthropic's entire strategy depends on being trusted as the safety-conscious actor in an industry increasingly defined by capability races. A disclosure that they've twice failed at basic process discipline undermines that narrative precisely when it's most important—regulators and enterprises are still deciding whether to believe that any AI company can be trusted with greater autonomy. The broader implication is darker: if the most safety-focused organization in the space struggles with operational execution at scale, the state of safety engineering across the industry is probably worse than publicly acknowledged.
The crucial questions ahead involve both immediate remediation and systemic change. Has Anthropic identified the root cause of the corruption mechanism, and can they credibly prevent recurrence? Will they publish transparent details, or bury this in technical documentation? More ambitiously: what does this reveal about the inadequacy of current AI safety infrastructure and tooling? As systems scale further, human oversight becomes distributed across thousands of engineers and processes become harder to audit. These failures suggest the industry may need fundamentally different approaches to maintaining control—perhaps immutable audit logs, automated process verification, or architectural changes that make these mistakes impossible rather than merely detectable after the fact.
This article was originally published on AI Alignment Forum. Read the full piece at the source.
Read full article on AI Alignment Forum →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to AI Alignment Forum. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.