AWS Machine Learning Blog

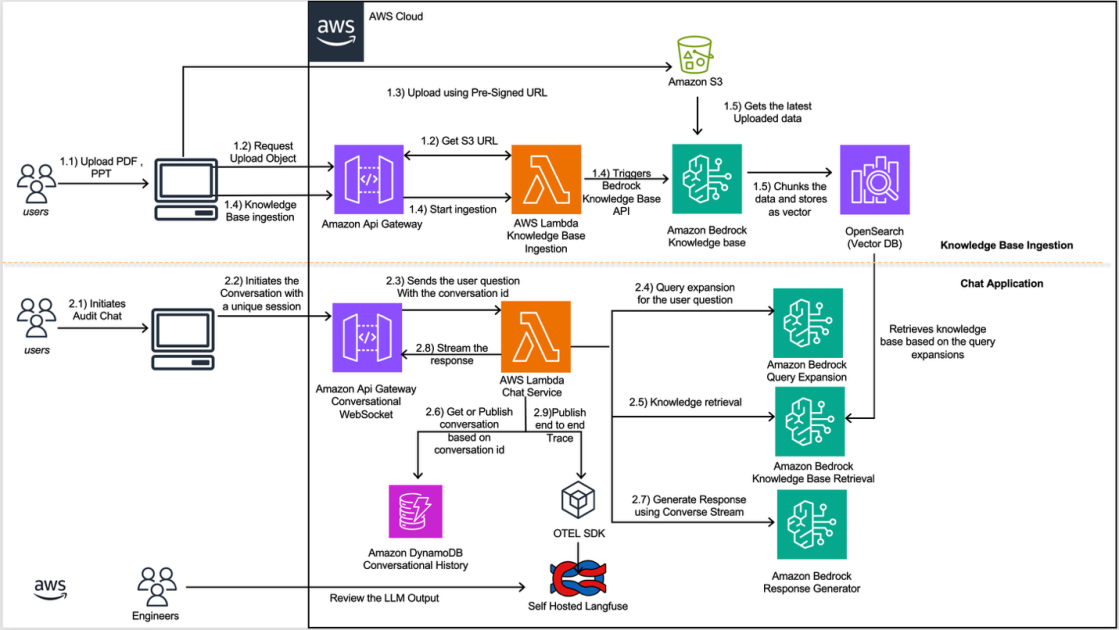
Amazon has released Nova Multimodal Embeddings, a new model that processes text and images into a unified vector space, allowing manufacturing companies to retrieve technical information regardless of whether answers live in written specifications or visual diagrams. The company built a production retrieval system on Bedrock and S3 Vectors, testing it against 26 real aerospace manufacturing queries where text-only systems consistently missed critical information embedded in engineering drawings, thermal plots, and inspection photographs. This represents a direct attack on a long-standing limitation in enterprise search: OCR-based text extraction flattens documents, stripping away the spatial relationships and visual encoding that often contain the most precise technical data. The announcement reframes multimodal AI not as a research curiosity but as table-stakes infrastructure for industries where engineering knowledge is inherently cross-modal.
Manufacturing has always been a multimodal domain, but enterprise tooling has treated images as secondary artifacts. A work order combines written assembly procedures with annotated photographs; an inspection report pairs numerical measurements with radiographic images; a material certification includes both tabular properties and fatigue curves. Yet search systems have universally converted images to text via OCR, accepting massive information loss as the cost of indexing. This created a perverse reality where searching manufacturing databases often missed the very documents that contained the answer, simply because the answer was encoded as a visual element. The problem compounds in capital-intensive industries like aerospace and automotive, where single design errors are extraordinarily expensive. Text-only retrieval made engineers hunt manually through documents they knew existed but couldn't find algorithmically. Multimodal embeddings eliminate this workaround by treating images and text as native search primitives.
The technical shift is subtle but consequential. Instead of OCR-first pipelines that convert images to strings before embedding, Nova processes images directly into the same vector space as text. A thermal contour plot becomes a discrete, searchable artifact; a labeled callout on a cross-section diagram can be found by a text query about bearing specifications. This opens a new category of cross-modal recall: engineers can upload a photograph of a completed assembly and retrieve the design specification that governed it, or query with text and retrieve the visual reference that illustrates it. For manufacturing, this is transformative because it removes the artificial separation between documentation types and lets organizations index and search technical knowledge as it actually exists. The competitive advantage accrues to teams that can move away from manual document review toward algorithmic retrieval that respects the full information structure of their archives.
The immediate beneficiaries are large manufacturers with sprawling, heterogeneous document repositories—aerospace, automotive, semiconductors, pharmaceuticals, any sector where regulatory compliance and design continuity require searchable archives of technical work. For these organizations, the cost of manual search is already high (engineer time spent digging through filing systems or scanning images by hand), and the cost of missed information is catastrophic (manufacturing delays, safety issues, compliance failures). Multimodal retrieval systems reduce search friction and increase recall, both of which map directly to operational efficiency and risk reduction. Beyond manufacturing, the same logic applies to any knowledge domain where information is distributed across text and images: medical imaging paired with radiology reports, geological surveys with seismic plots, legal discovery with scanned contracts, academic research with figure-heavy papers. AWS is essentially democratizing a capability that only the largest enterprises could afford to build custom.
Amazon's move also reflects a broader shifting balance in the AI value chain. For years, the advantage accrued to companies that could afford to train proprietary models on proprietary data. Now the advantage is consolidating around companies that can offer foundational multimodal capabilities as managed services, allowing enterprises to index their unique datasets without rebuilding infrastructure. This commoditizes a layer of the stack that used to require months of specialized engineering. It also puts pressure on competitors like Google, Microsoft, and Anthropic to offer equivalent multimodal embedding services; this is no longer optional innovation, it's table-stakes. The underlying message from AWS is clear: multimodal AI is mature enough for production workloads, specific enough to solve real manufacturing problems, and cost-effective enough to be offered as a service rather than an internal R&D project.
The next critical question is adoption velocity. Manufacturing enterprises move slowly, and integrating a new retrieval backend into decades-old document management systems will require integration work. The compelling test case here is whether the 26-query evaluation translates into real production deployments, and whether enterprises with less technical depth than aerospace leaders can successfully operationalize multimodal retrieval. There's also the open question of where else multimodal embeddings create similar asymmetries in existing systems—technical documentation, regulatory archives, academic literature, patent databases, medical records. As these use cases accumulate, the competitive pressure on other cloud providers will intensify. The broader shift suggests that we're moving past the era of text-only AI tooling into one where visual information is treated as equally primary, which will unlock new categories of knowledge work that were previously too expensive to automate.
This article was originally published on AWS Machine Learning Blog. Read the full piece at the source.
Read full article on AWS Machine Learning Blog →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to AWS Machine Learning Blog. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.




