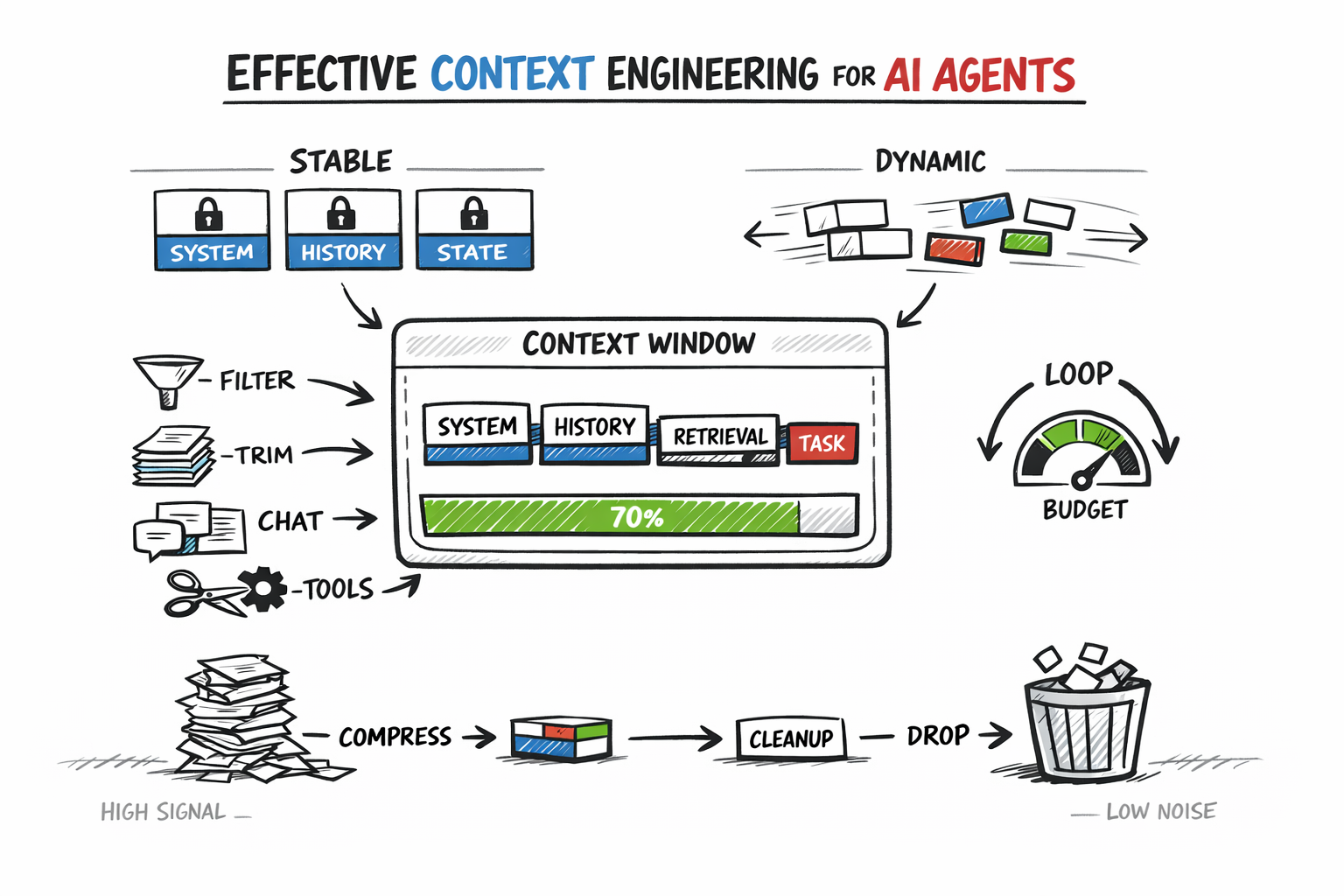
The economics of agentic AI just shifted. Machine Learning Mastery's latest piece on prompt compression highlights an increasingly urgent engineering challenge: the runaway cost structure of production AI agents. As frameworks like LangGraph and AutoGPT push multi-step reasoning into production, the financial model breaks down faster than most developers expect. This isn't a theoretical concern anymore—it's shaping architectural decisions across the industry right now, and the techniques available to address it are still fragmented and immature.
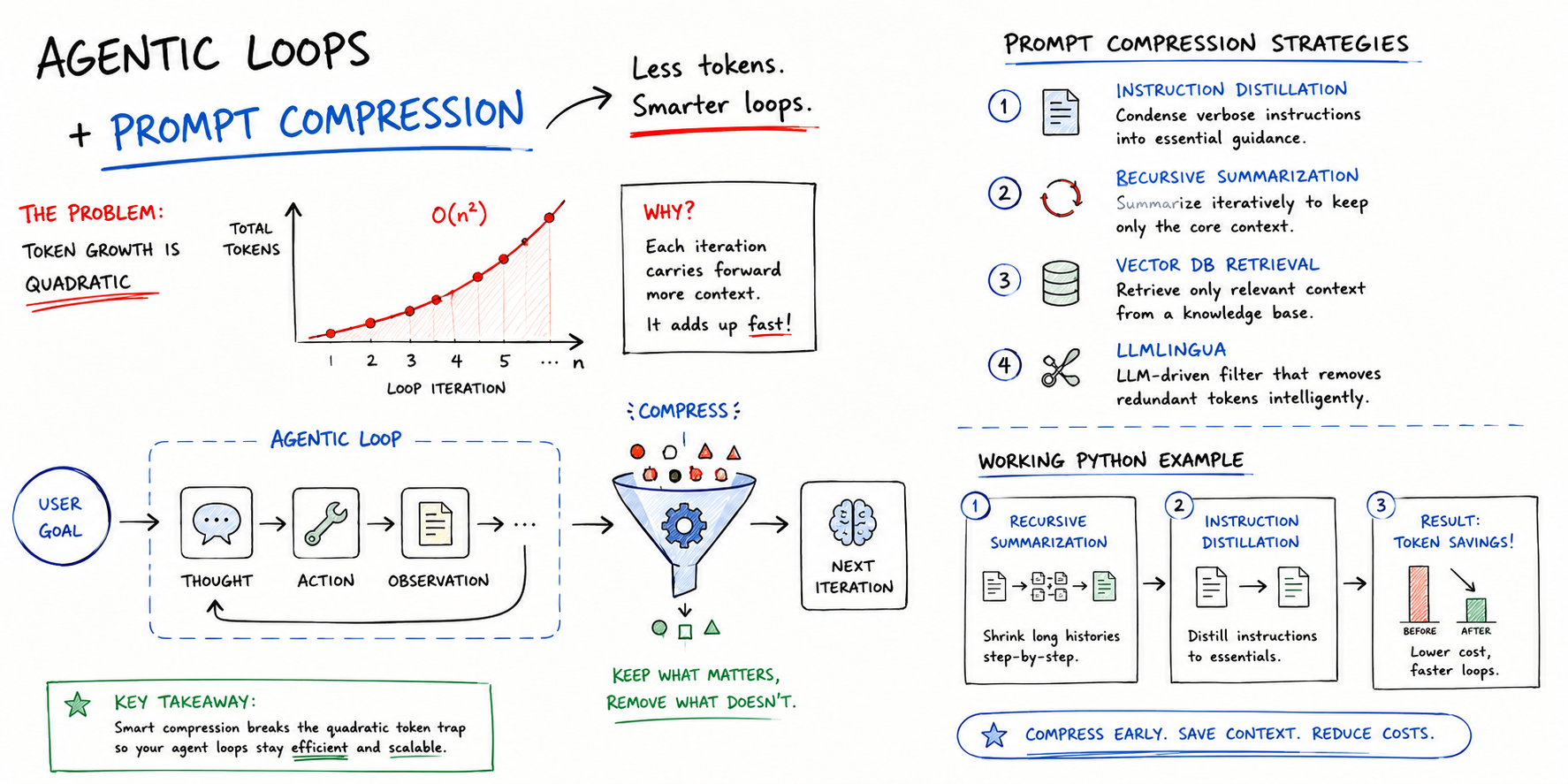
The underlying problem is deceptively simple but devastating in scale. Each step in an agentic loop carries forward all previous context, creating a compounding effect where token consumption accelerates geometrically rather than linearly. An agent solving a ten-step problem doesn't send fifty percent more tokens per step—it sends exponentially more, because every new step must carry the full weight of everything before it. This makes the difference between a five-step agent that costs dollars and a twenty-step agent that costs hundreds. The latency tax is equally brutal: longer prompts mean longer inference times, which translates directly to user frustration in production systems. The article frames this as the hidden cost of reasoning—not just in dollars, but in wall-clock time.
Why this matters is organizational and strategic. Prompt compression shifts from being a nice-to-have optimization to a core requirement for any company deploying agents at scale. The techniques described—instruction distillation, recursive summarization, vector retrieval, and specialized algorithms like LLMLingua—are all viable, but none has emerged as a clear winner. This creates a landscape where engineering teams are making ad-hoc decisions about compression strategies without industry consensus, which means repeated invention and suboptimal implementations across teams. More critically, it means some companies will solve this problem elegantly and gain a structural cost advantage over competitors, while others will deploy agents that become economically unsustainable within months of production launch.
The impact flows through different constituencies differently. For developers, this means prompt compression is now a mandatory skill for agents work—no longer optional. For enterprises, it determines whether AI agents remain viable as a business case or become relegated to high-value scenarios where cost doesn't matter. For cloud providers and API vendors like Anthropic, this creates pressure to build compression capabilities directly into their platforms; the companies shipping compression tools and SDKs will capture significant value. The researchers working on compression techniques have moved from academic curiosity into practical necessity, which typically accelerates maturity and standardization.
The competitive angle is sharp. Teams that can reduce a 500K-token context to 32K while preserving semantic meaning gain a five-fold efficiency advantage. In markets where margins are thin and inference volumes are massive, this translates to real profitability. It also opens doors to applications that previously seemed economically infeasible—agents that were too expensive to deploy for mid-market customers suddenly become viable. This could accelerate the distribution of agentic systems beyond the Fortune 500, making it a societal multiplier for wherever AI agents actually deliver value.
What comes next will determine whether compression remains a toolkit of scattered techniques or becomes an industry standard. Watch for three signals: whether major frameworks begin shipping compression as a default layer rather than leaving it to application developers, whether specialized compression vendors emerge (or whether existing observability platforms absorb this capability), and whether the cost delta between compressed and uncompressed agents becomes a standard metric in benchmarks and case studies. The real inflection point arrives when teams start failing agent deployments not because the reasoning is broken, but because the cost curve killed the business model. That inflection is likely months away, and the companies that move first on compression will own significant advantage territory.
This article was originally published on Machine Learning Mastery. Read the full piece at the source.
Read full article on Machine Learning Mastery →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to Machine Learning Mastery. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.