NVIDIA AI Blog

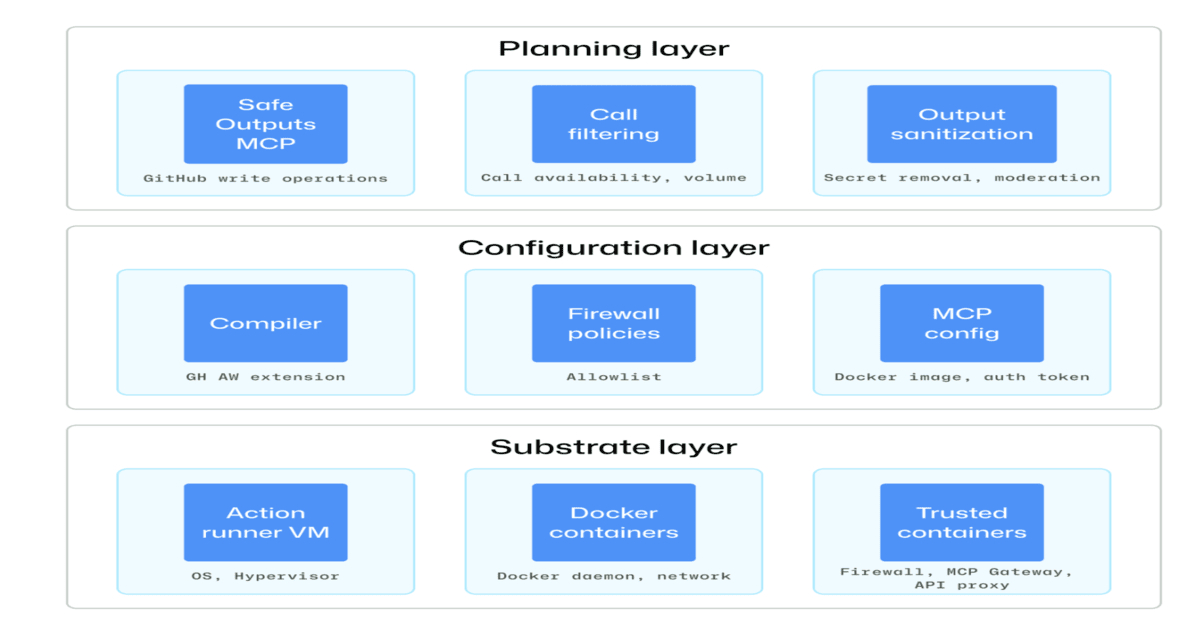
OpenAI has published a detailed breakdown of its internal governance model for Codex, the autonomous coding agent that can review repositories, execute commands, and interact with development tools independently. Rather than positioning Codex as a black box or a cautionary tale requiring extreme lockdown, OpenAI describes a pragmatic middle path: deploying agents within technical boundaries while automating low-friction approval for routine, predictable actions. The framework combines sandboxing at the execution layer, tiered approval policies that distinguish high-risk from routine operations, network restrictions that whitelist known-safe destinations, credential management through OS keyrings, and differential treatment of shell commands based on risk severity. The framing is notably operational—these are architectural and policy choices made across multiple enforcement layers rather than a single silver-bullet control mechanism.
The timing of this disclosure reflects broader industry pressure. As AI systems move from chatbots to agents that can actually *do* things—modifying code, triggering deployments, accessing internal systems—the burden of governance shifts from individual developers to security and platform teams. Enterprise buyers have demanded this level of detail, and understandably so: an autonomous agent with uncontrolled network access or credential scope becomes a massive attack surface. OpenAI's move to articulate this model is partly defensive, demonstrating that they've thought through the problems that competitors and critics have raised. It's also partly a definition game: by publishing their approach, they're implicitly setting a baseline for what "safe agent deployment" should look like, which matters when other labs and companies inevitably deploy their own agents.
The substance here reveals an important shift in how AI safety is being operationalized. Rather than abstract principles, OpenAI is describing concrete enforcement points: auto-approval subagents that can veto Codex's own actions based on risk heuristics, managed network policies that don't assume agents are trustworthy enough for open internet access, and audit logs that preserve agent-native telemetry. This moves safety from the realm of "responsible AI" rhetoric into the realm of access control and compliance—the same mechanisms enterprises already understand from traditional software governance. The auto-review concept is particularly clever: it offloads the legitimacy check to another AI system, which means humans don't have to sit in a loop approving routine actions, but also means there's a second model whose decisions can be audited and learned from. This is less about preventing bad outcomes through restriction and more about building confidence through oversight and transparency.
The practical impact will be felt most acutely by enterprise security teams who have been caught between developer pressure to ship faster and their responsibility to prevent runaway agents from accidentally (or deliberately) exfiltrating code or credentials. OpenAI's sandboxing approach—defining exactly where Codex can write, whether it can reach the network, and which paths are protected—gives security teams a language for these conversations that's more precise than "we're worried about what the AI might do." For developers, the promise is friction reduction: if you're making a routine code review check or running a known-safe command, you don't wait for approval; OpenAI's auto-review handles it. This creates a two-tier system where trust is proportional to risk, which is sensible, but also introduces a new attack surface: gaming the auto-approval system by making high-risk actions look like low-risk ones.
Competitively, this announcement positions OpenAI ahead of other labs that haven't disclosed their agent safety practices. Anthropic, which has been more vocally focused on safety, hasn't published equivalent operational detail. Google's ecosystem is fragmented across Gemini agents, Vertex, and Cloud Run. Most startups building coding agents have probably thought less deeply about these governance layers than OpenAI has publicly admitted. The implication is clear: if you're an enterprise considering which coding agent to deploy, OpenAI is claiming not just capability but governance maturity. Whether that's warranted depends on whether OpenAI's practices are actually more robust than competitors', or just more transparently communicated—a distinction that matters but is hard for customers to verify without similar disclosure from rivals.
The open questions are significant. How effective is auto-approval in practice—does it approve too much, too little, or does it create a false sense of safety? What happens when agents encounter novel scenarios that don't fit the pre-defined approval profiles? Can the network whitelisting scale as agents need access to new internal systems, or does it become brittle? And perhaps most importantly: who bears liability when a Codex agent, even within all these constraints, causes damage? OpenAI's approach makes safety *visible* and *measurable*, which is progress, but doesn't eliminate the fundamental question of whether autonomous agents should have direct access to critical systems in the first place. That's a policy question above any single company's architecture choices.
This article was originally published on OpenAI Blog. Read the full piece at the source.
Read full article on OpenAI Blog →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to OpenAI Blog. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.