Analytics Vidhya
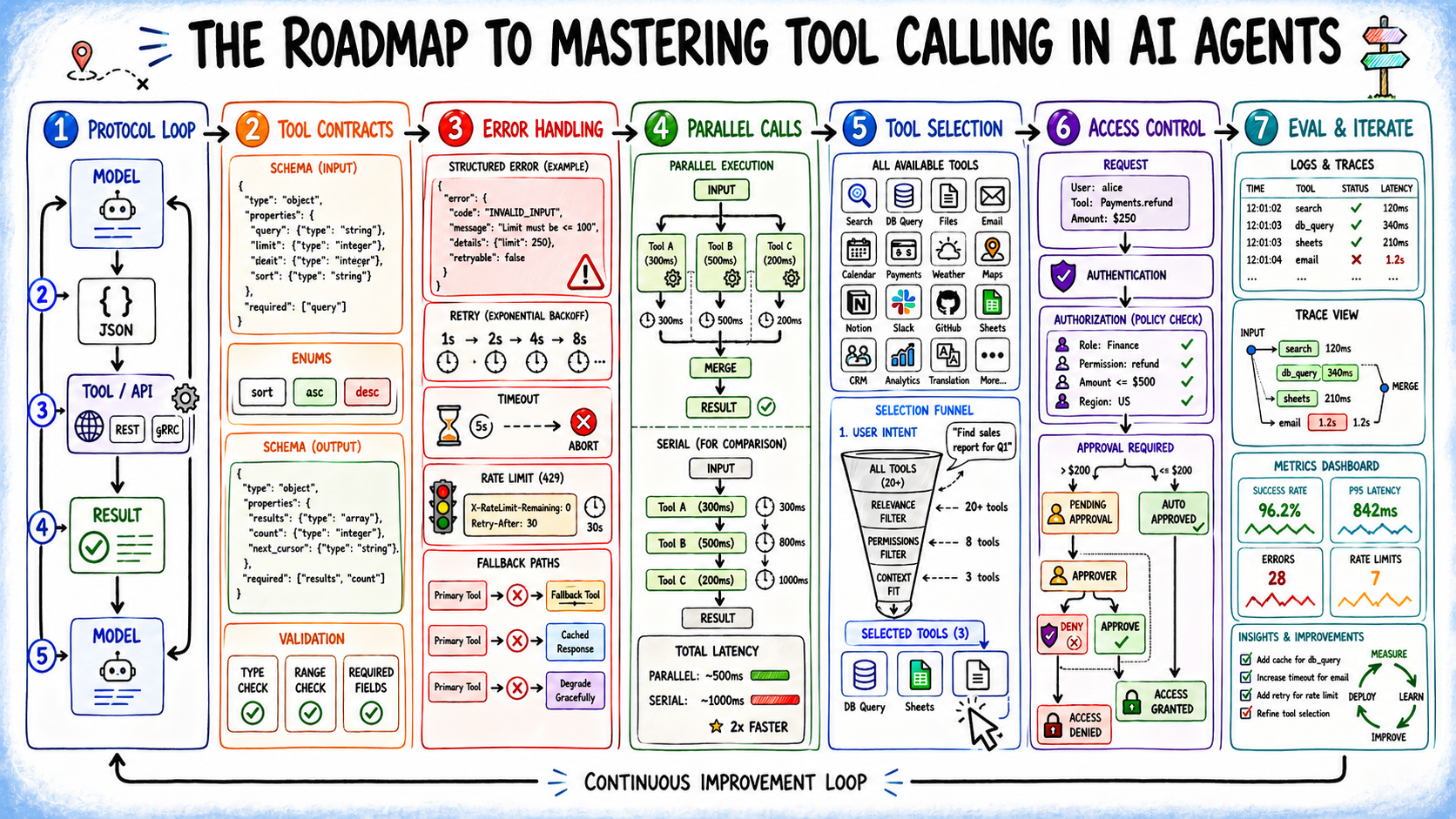
Machine Learning Mastery's guide to tool calling in AI agents reframes a deceptively simple concept as the actual fault line in production AI systems. The article dissects tool calling—the protocol that connects language model reasoning to executable actions—not as an afterthought API integration but as a distinct architectural layer where most real production failures occur. Rather than dwelling on model intelligence or prompt engineering, the piece redirects attention to where agents actually break: malformed arguments, unhandled errors, wrong tool selection, and execution failures that no amount of reasoning capacity fixes. This perspective matters because the industry's public discourse fixates on model capabilities while the engineering reality sits in unglamorous but critical plumbing.
The timing reflects where AI deployment has matured. Early-stage agent work could abstract away tool calling complexity—slap a retrieval tool here, an API call there, and declare victory. But as enterprises move agents into production, the hidden costs become visible. Tool catalogs grow. Parallel execution needs discipline. Error handling compounds in complexity. Security boundaries blur when agents can trigger transactions or modify databases. The article captures a specific inflection point: tool calling has shifted from a minor integration detail to a first-class architectural concern. This aligns with broader industry movement from prototype-to-production, where hidden assumptions in toy systems become load-bearing failures at scale.
The strategic significance lies in redefining what "production-ready" means for AI agents. Vendors and open-source frameworks have largely treated tool calling as orthogonal to their core offerings, focusing engineering effort on model quality while leaving integration patterns to users. This article implicitly argues that's backwards—that tool calling reliability directly constrains how intelligently an agent can actually behave in the real world. A 95% accurate reasoning layer paired with a brittle, unreliable execution layer nets out to a 60% effective agent. This reframing creates space for tooling companies to build genuine value at the execution layer: frameworks that handle parallelization, validation, error recovery, and security without forcing users to reinvent it for every deployment. It suggests the next wave of competitive differentiation won't come from who has the smartest base model, but who makes tool calling invisible and bulletproof.
The impact lands hardest on application engineers shipping AI systems into enterprises. This audience faces the unvarnished reality: their agents are only as reliable as their tool layer, and validation, error handling, and security are non-optional. For researchers and model builders, the article serves as a sobering reality check—spending cycles on reasoning improvements yields limited gains if the execution layer wastes them. Enterprise decision-makers should recognize this as a signal that buying a model isn't buying an agent; buying an agent requires reckoning with tool infrastructure as a first-order investment. Startups building agent platforms have a clear opening to differentiate by solving tool calling robustness, not just by bolting on better model access.
Competitively, this analysis elevates tool calling as a moat. OpenAI, Claude, Gemini, and other model providers all expose tool calling APIs, but they've largely commoditized the interface while leaving orchestration and reliability to users. Any platform that absorbs that complexity—providing battle-tested patterns for parallelization, security, error recovery, and validation—creates friction for switching. The article quietly suggests that the next generation of AI infrastructure won't be model providers competing on reasoning, but orchestration layers competing on making tool calling bulletproof. Smaller models paired with excellent tool calling could out-perform expensive large models paired with brittle execution.
The forward-looking angle hinges on unsolved problems the article identifies but doesn't fully resolve: How do you scale tool catalogs without degrading model performance? When should agents run tools in parallel versus sequentially? How do you secure a system where agents can trigger real transactions? How do you evaluate tool calling quality independent of task outcomes? These questions suggest the field is moving from "can we do tool calling" to "can we do it reliably at enterprise scale," and that maturation is where real value and competitive advantage will concentrate. The next wave of tooling will be measured not in model parameters but in uptime, latency, error recovery, and audit trail—the infrastructure metrics that separate hobby AI from production AI.
This article was originally published on Machine Learning Mastery. Read the full piece at the source.
Read full article on Machine Learning Mastery →DeepTrendLab curates AI news from 50+ sources. All original content and rights belong to Machine Learning Mastery. DeepTrendLab's analysis is independently written and does not represent the views of the original publisher.